Chunking en RAG: qué es y cómo elegir la estrategia correcta
Guía completa de chunking en RAG: qué es, todas las estrategias (fixed-size, semantic, agentic, late chunking), cómo elegir y cómo evaluarlo en producción.
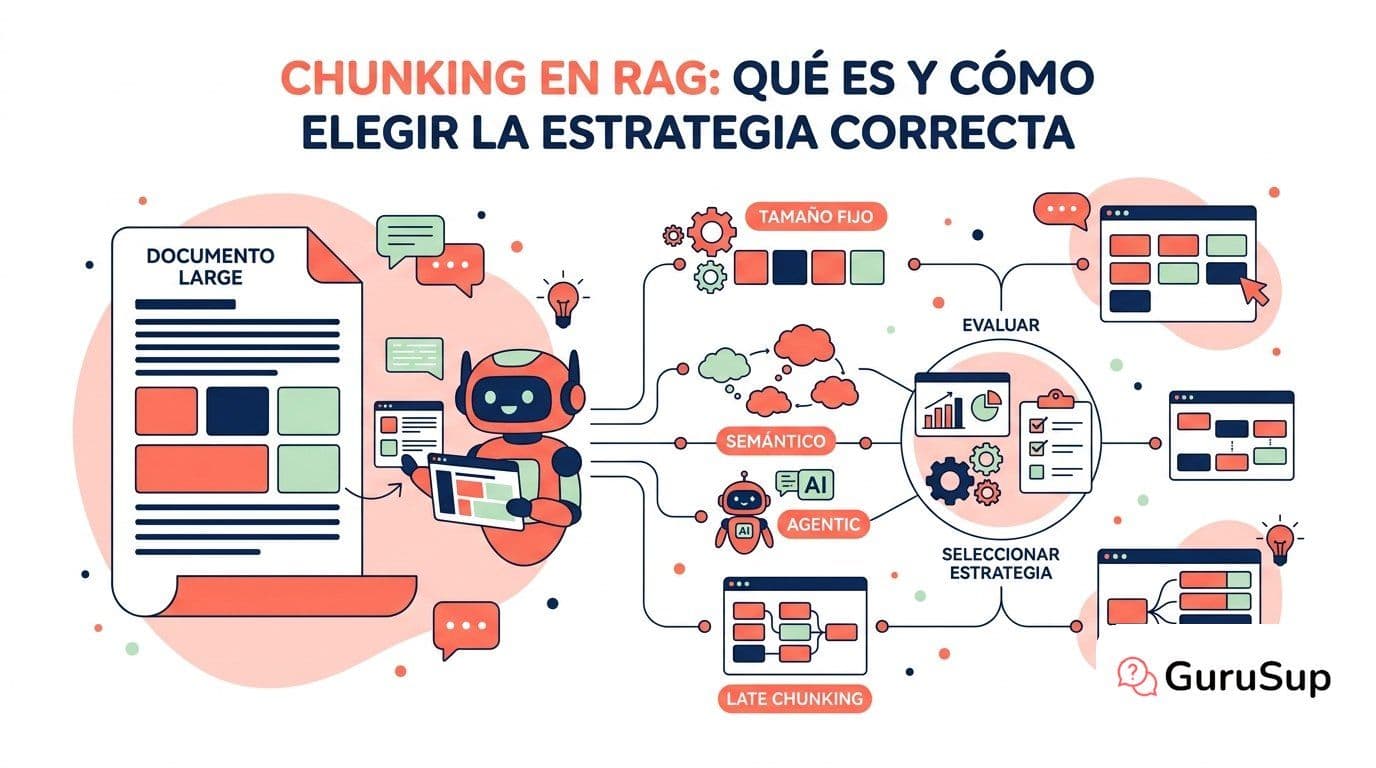
Tabla de contenidos
- ¿Qué es el chunking en RAG?
- ¿Por qué el chunking es la decisión más importante de tu pipeline RAG?
- Estrategias de chunking, de la más simple a la más avanzada
- Tabla comparativa de estrategias de chunking
- Herramientas para implementar chunking en Python
- Chunking dentro del pipeline RAG completo
- ¿Qué estrategia de chunking usar según tu caso?
- ¿Cómo optimizar el chunk size en producción?
- Preguntas frecuentes sobre chunking en RAG
- Empieza simple y mide
Montas tu primer sistema RAG, le enchufas toda la documentación de tu empresa, haces la primera pregunta de prueba… y el agente te suelta una respuesta que mezcla tres documentos que no venían a cuento. No es culpa del modelo. No son los embeddings. Casi siempre es el chunking: cómo has partido esos documentos antes de guardarlos.
En GuruSup llevamos años montando agentes de IA que leen bases de conocimiento enteras para responder a clientes reales, y si algo hemos aprendido es que el chunking es la decisión que más condiciona la calidad de un RAG y, a la vez, la que más se hace a ojo. En esta guía te cuento qué es exactamente el chunking, todas las estrategias que existen (de la más simple a la más avanzada), cómo elegir la tuya según el tipo de documento y, sobre todo, cómo saber si la que has elegido funciona de verdad.
¿Qué es el chunking en RAG?
El chunking es el proceso de partir un documento en fragmentos más pequeños —los chunks— antes de convertirlos en embeddings y guardarlos en una base de datos vectorial (vector database). Cuando un usuario hace una pregunta, el sistema RAG no busca en el documento entero: busca los chunks más parecidos a la pregunta y se los pasa al modelo como contexto.
Dicho de otro modo: el chunk es la unidad mínima que tu agente puede recuperar. Si partes mal, recuperas mal. Y si recuperas mal, el modelo responde mal por muy potente que sea. Por eso el chunking no es un detalle de preprocesado, es una decisión de arquitectura.
¿Por qué el chunking es la decisión más importante de tu pipeline RAG?
Un LLM tiene un context window limitado y, lo que es más importante, no presta la misma atención a todo lo que le metes dentro. Si le pasas un chunk gigante con la respuesta enterrada en medio, el modelo tiende a pasarla por alto: es el fenómeno del "lost in the middle" que documentaron Liu et al. en 2023. Y si le pasas un chunk minúsculo, le falta contexto para entender de qué va.
El problema de los chunks demasiado grandes
Un chunk grande mete mucho contexto, sí, pero también mucho ruido. Al calcular el embedding, el "tema" del fragmento se diluye: un chunk que habla de cinco cosas a la vez no se parece de verdad a ninguna pregunta concreta. Resultado: el retrieval pierde precisión y recuperas fragmentos que tocan tu tema de refilón.
El problema de los chunks demasiado pequeños
Al revés, un chunk demasiado pequeño es muy preciso pero se queda sin contexto. Recuperas la frase exacta, pero el modelo no sabe a qué se refería el párrafo, quién es el sujeto o de qué apartado venía. La respuesta sale coja o, peor, el modelo rellena el hueco inventando: ahí es donde aparecen las hallucinations.
El equilibrio: precisión en el retrieval + contexto para el modelo
El buen chunking busca el punto en el que cada fragmento es lo bastante específico para recuperarse bien y lo bastante completo para que el modelo lo entienda solo. Ese punto no es un número mágico universal: depende del tipo de documento y de las preguntas que esperas. Por eso lo que sigue no es una receta única, sino un mapa de estrategias.
¿Cuándo NO necesitas hacer chunking?
Antes de complicarte: si tus "documentos" ya son cortos y autocontenidos —una FAQ donde cada entrada es una pregunta y su respuesta, fichas de producto, tickets individuales— probablemente no necesites partir nada. Cada registro ya es un chunk natural. Forzar un chunking encima solo añade complejidad. El chunking resuelve un problema de documentos largos; si no lo tienes, no inventes uno.
Estrategias de chunking, de la más simple a la más avanzada
Fixed-size chunking
Fixed-size chunking: partir cada N tokens (o caracteres), normalmente con un poco de solape. Es la estrategia por defecto y la más rápida de implementar. Su pega es obvia: corta por donde toque, aunque sea a mitad de una frase o de una tabla. Como punto de partida funciona; como solución final, rara vez.
Sentence-based y paragraph-based chunking
Sentence/paragraph chunking: en lugar de cortar por número de tokens, cortas por frases o por párrafos completos usando un tokenizador lingüístico (NLTK, spaCy). Respetas la unidad de significado natural del texto. Va bien con prosa ordenada; sufre con documentos de estructura irregular.
Sliding window (overlap)
Sliding window (overlap): aquí entra el overlap: cada chunk comparte un trozo del anterior. Así evitas que una idea que cae justo en el corte se quede huérfana entre dos fragmentos. Un overlap del 10-20% del tamaño del chunk es un punto de partida razonable. Es barato y casi siempre mejora el recall.
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Recursive chunking
Recursive chunking: la estrategia más usada en producción. Intentas partir por los separadores más "fuertes" primero (saltos de párrafo), y solo si el fragmento sigue siendo demasiado grande bajas al siguiente nivel (saltos de línea, frases, palabras). Es lo que hace el `RecursiveCharacterTextSplitter` de LangChain. Respeta la estructura del texto mucho mejor que el fixed-size sin complicarte la vida.
Document-based chunking
Document-based chunking: cortas usando la estructura real del documento: encabezados Markdown, etiquetas HTML, funciones en código fuente, secciones de un PDF. Para documentación técnica o legal, donde la jerarquía importa, es de lo mejor que puedes hacer: cada chunk hereda su contexto estructural (a qué apartado pertenece).
Semantic chunking
Semantic chunking: en vez de cortar por forma, cortas por significado. Calculas embeddings de frases consecutivas y abres un chunk nuevo cuando detectas un salto temático (la distancia entre frases supera un umbral). Produce chunks muy coherentes, pero cuesta más cómputo y hay que ajustar el umbral. Brilla cuando el documento salta de tema sin avisar.
LLM-based y contextual chunking
LLM-based chunking: le pides a un modelo que parta el documento de forma inteligente o, mejor todavía, que añada a cada chunk un pequeño resumen del contexto del que viene —el contextual retrieval que propuso Anthropic—. Mejora mucho el retrieval porque cada fragmento "se explica solo", a costa de un preprocesado más caro.
Agentic chunking
Agentic chunking: un agente decide, fragmento a fragmento, dónde cortar y cómo agrupar las ideas, como lo haría un humano que resume. Es lo más sofisticado y lo más caro. Tiene sentido en corpus pequeños y muy valiosos donde la calidad lo justifica; para millones de documentos, todavía no sale a cuenta.
Late chunking
Late chunking: le das la vuelta al orden clásico: primero pasas el documento largo entero por el modelo de embeddings (aprovechando su context window) y partes después, ya con la información del contexto global "dentro" de cada fragmento. Es una técnica reciente de Jina AI que mejora los casos donde el significado depende de referencias lejanas (pronombres, "lo anterior", "dicha cláusula").
Hierarchical chunking y parent-document retrieval
Hierarchical chunking: guardas chunks pequeños para buscar con precisión, pero cuando recuperas uno, le pasas al modelo el chunk padre más grande del que venía. Lo mejor de los dos mundos: precisión en el retrieval, contexto en la generación. El `ParentDocumentRetriever` de LangChain implementa justo esto, y es de las técnicas que más rendimiento da con menos esfuerzo.
Tabla comparativa de estrategias de chunking
- Fixed-size — Coste: Muy bajo · Calidad de contexto: Baja · Cuándo usarla: Prototipo rápido / baseline
- Sentence / paragraph — Coste: Bajo · Calidad de contexto: Media · Cuándo usarla: Prosa bien estructurada
- Sliding window (overlap) — Coste: Bajo · Calidad de contexto: Media-alta · Cuándo usarla: Casi siempre, combinable
- Recursive — Coste: Bajo · Calidad de contexto: Alta · Cuándo usarla: Default de producción
- Document-based — Coste: Medio · Calidad de contexto: Alta · Cuándo usarla: Legal, técnica, código
- Semantic — Coste: Medio-alto · Calidad de contexto: Alta · Cuándo usarla: Documentos que saltan de tema
- Contextual / LLM-based — Coste: Alto · Calidad de contexto: Muy alta · Cuándo usarla: Corpus valioso, alta exigencia
- Agentic — Coste: Muy alto · Calidad de contexto: Muy alta · Cuándo usarla: Corpus pequeño y crítico
- Late chunking — Coste: Medio · Calidad de contexto: Muy alta · Cuándo usarla: Mucha referencia cruzada
- Parent-document — Coste: Bajo-medio · Calidad de contexto: Muy alta · Cuándo usarla: Mejor relación calidad/esfuerzo
Herramientas para implementar chunking en Python
- LangChain: `RecursiveCharacterTextSplitter` para el recursive de toda la vida y `ParentDocumentRetriever` para la jerarquía padre-hijo. Es el punto de entrada más cómodo.
- LlamaIndex: su `HierarchicalNodeParser` y los node parsers semánticos están muy pensados para RAG desde el primer día.
- NLTK y spaCy: cuando necesitas un sentence splitting fino y respetuoso con el idioma (importante en español, donde las abreviaturas engañan a los splitters ingenuos).
Chunking dentro del pipeline RAG completo
El chunking no vive solo. Es la primera pieza de una cadena, y de poco sirve afinarlo si descuidas el resto. Si todavía no tienes claro qué es RAG y para qué sirve el pipeline completo, el punto de partida es nuestra guía sobre qué es RAG.
Chunking + embeddings + base de datos vectorial
Cada chunk se convierte en un embedding y se guarda en la base de datos vectorial. El tamaño del chunk debe ir acorde al modelo de embeddings que uses: no tiene sentido meter 2.000 tokens en un modelo pensado para 512.
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Búsqueda híbrida: vectorial + BM25
La búsqueda puramente vectorial falla con nombres propios, códigos de producto o siglas. Combinarla con BM25 (búsqueda léxica clásica) recupera lo mejor de ambos mundos. En atención al cliente, donde el cliente escribe el número de pedido o el nombre exacto del plan, la híbrida marca la diferencia.
Reranking con cross-encoder: el paso que casi nadie usa
Después de recuperar los candidatos, un reranker (cross-encoder) los reordena por relevancia real antes de pasárselos al modelo. Es barato comparado con lo que aporta y, junto con un buen chunking, es de los cambios que más suben la calidad de las respuestas. Aun así, en la mayoría de tutoriales en español ni se menciona.
¿Cómo evaluar si tu chunking funciona?
Aquí está la parte que casi nadie cuenta y que separa un RAG de juguete de uno de producción: medir. No cambies tu estrategia de chunking por intuición. Monta un set de preguntas reales con sus respuestas esperadas y mide con herramientas como RAGAS: *context precision* (¿lo que recuperas es relevante?), *context recall* (¿recuperas todo lo que hace falta?) y *faithfulness* (¿la respuesta se ciñe a lo recuperado o se lo inventa?). Cuando puedes comparar dos estrategias con números, dejas de discutir y empiezas a decidir.
¿Qué estrategia de chunking usar según tu caso?
- Documentos legales y contratos: document-based por cláusulas + parent-document. La estructura es sagrada y el contexto de la cláusula importa tanto como su texto.
- Código fuente: partir por funciones/clases (document-based sobre el AST), nunca por número de líneas.
- Documentación técnica y manuales: recursive respetando los encabezados + overlap. Cada chunk hereda su sección.
- Atención al cliente y FAQs: si cada FAQ es corta, una entrada por chunk y a correr. Para manuales de producto largos, recursive + parent-document. Este es el terreno donde un agente de IA para atención al cliente bien alimentado responde como tu mejor agente humano, y donde el chunking decide si acierta o marea. El destino final de esos chunks bien construidos es la base de conocimiento con IA: la fuente de verdad que el agente consulta en cada conversación.
- Contenido web y PDFs: limpia primero el ruido (menús, footers) y luego recursive. Un PDF mal extraído arruina cualquier estrategia posterior.
¿Cómo optimizar el chunk size en producción?
Punto de partida sensato
Un buen baseline para empezar: chunks de en torno a 512 tokens con un overlap de 50-100, estrategia recursive. No porque sea óptimo, sino porque es un punto medio del que partir para medir.
Testea tamaños y quédate con datos, no con corazonadas
Prueba varias combinaciones de tamaño y overlap contra tu set de evaluación. Verás que el tamaño ideal cambia según tus documentos y tus preguntas. Lo que funciona en la documentación de una fintech no funciona en el catálogo de un ecommerce.
Chunk expansion como post-proceso
Chunk expansion: una técnica sencilla y efectiva: recuperas con chunks pequeños (precisos) pero, antes de generar, expandes cada uno con sus vecinos para dar contexto al modelo. Es el espíritu del parent-document llevado al runtime.
Preguntas frecuentes sobre chunking en RAG
¿Cuál es el mejor tamaño de chunk? No hay uno universal. Empieza por ~512 tokens con overlap y ajústalo midiendo contra tus propias preguntas.
¿Chunking o fine-tuning? Resuelven problemas distintos. El chunking (dentro de RAG) sirve para que el modelo responda con tu información actualizada; el fine-tuning, para cambiar su comportamiento o estilo. En la mayoría de casos de empresa, empiezas por RAG.
¿El overlap siempre ayuda? Casi siempre mejora el recall, pero infla el número de chunks y el coste de almacenamiento. Un 10-20% suele ser buen equilibrio.
¿Necesito semantic o agentic chunking desde el principio? No. Empieza por recursive + parent-document, mide, y solo sube de complejidad si los números lo piden.
Empieza simple y mide
Para un primer RAG, recursive chunking con overlap y parent-document retrieval te resuelve la mayoría de los casos. El resto es trabajo de medición: un set de preguntas reales, RAGAS, y cambiar de estrategia cuando los números lo pidan. Nada de afinar a ojo.
Nosotros montamos este pipeline entero —chunking, búsqueda híbrida, reranking y evaluación— para los agentes que atienden a clientes sobre la documentación de cada empresa. Si tu RAG recupera regular, mira nuestro software de base de conocimiento con IA.