¿Qué es el prompt engineering? Guía para agentes de IA
Qué es el prompt engineering, cómo funcionan las técnicas principales (zero-shot, few-shot, chain-of-thought, role prompting) y cómo aplican a los agentes de IA que atienden a tus clientes.
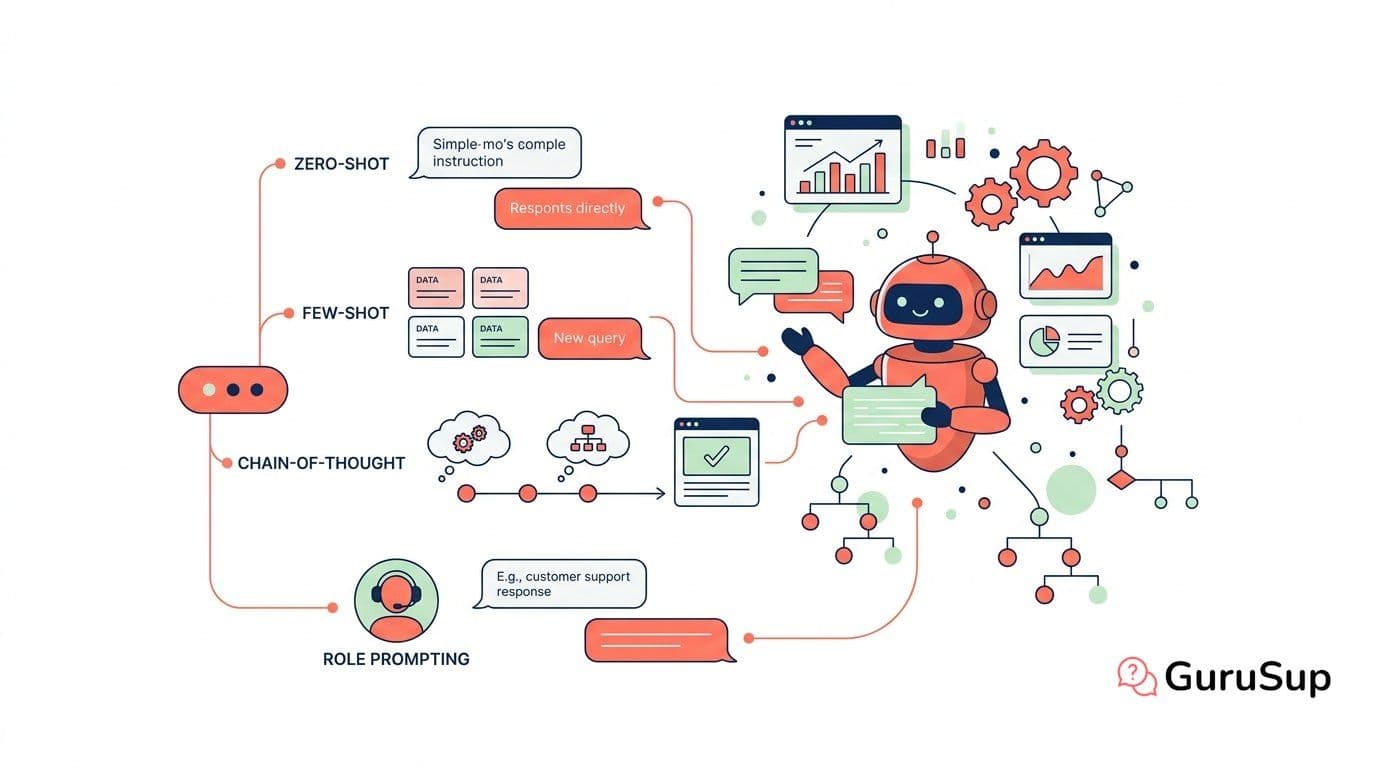
Tabla de contenidos
- ¿Por qué el prompt engineering decide la calidad de tu agente?
- ¿Cómo funciona un LLM sin contexto externo?
- ¿Cuáles son las técnicas de prompt engineering que realmente importan?
- ¿Qué tabla comparativa tienen las técnicas de prompt engineering?
- ¿Cómo cambia el prompt engineering cuando el modelo tiene herramientas?
- ¿Cuándo el prompt engineering no es suficiente?
- ¿Cuáles son los errores más comunes de prompt engineering en agentes reales?
- ¿Cómo afecta el prompt engineering a la calidad de tu agente de atención al cliente?
- ¿Cuál es el proceso de mejora del prompt en producción?
- Preguntas frecuentes sobre prompt engineering
Lanzas un agente de IA para responder a tus clientes. Le das acceso a la documentación de tu empresa, le conectas al CRM, y te preparas para ver la magia. Primera conversación: el agente responde de forma vaga, cambia de tono a mitad del mensaje, y cuando el cliente le pregunta algo fuera del guión, improvisa. No mal, pero tampoco bien. No es culpa del modelo. Casi nunca lo es. Es el prompt engineering — o más exactamente, la ausencia de él.
En GuruSup llevamos tiempo montando agentes de IA que gestionan conversaciones reales con clientes de empresas, y si hay una variable que explica la diferencia entre un agente que resuelve y uno que marea, esa variable es cómo está diseñado el prompt. En esta guía te cuento qué es el prompt engineering exactamente, qué técnicas importan de verdad, cómo cambia todo cuando el modelo tiene herramientas, y cuándo el prompt ya no es suficiente y necesitas otra cosa.
¿Por qué el prompt engineering decide la calidad de tu agente?
Antes de entrar en técnicas, hay que entender el problema de raíz. Un LLM (Large Language Model) es, en esencia, una función de probabilidad: dado un texto de entrada, predice qué texto tiene más probabilidades de venir después. No tiene objetivos propios. No tiene criterio intrínseco sobre qué es una buena respuesta para tu caso de uso. Lo que le metas dentro es lo que decide lo que sale.
Cuando usas ChatGPT de forma casual, esa imprecisión no importa mucho: si la respuesta no es perfecta, la reformulas. Pero cuando el modelo atiende a cientos de clientes al día sin que tú estés mirando, necesitas que se comporte de forma predecible, coherente y útil en cada interacción. Ahí es donde entra el prompt engineering: la disciplina de diseñar las instrucciones que le das al modelo para que ese comportamiento sea consistente.
Dicho de otro modo: el model no lee la mente de tu negocio. El prompt engineering es el puente entre lo que quieres que haga tu agente y lo que el modelo es capaz de hacer.
¿Cómo funciona un LLM sin contexto externo?
Para entender qué puedes controlar con el prompt, primero hay que saber qué controla el modelo internamente.
Un LLM ha sido entrenado con cantidades masivas de texto. Ese entrenamiento le da un conocimiento general amplísimo — sabe escribir código, explicar conceptos, resumir documentos, responder preguntas — pero ese conocimiento es estático: refleja lo que había en los datos de entrenamiento hasta una fecha de corte. No sabe qué está pasando en tu empresa hoy. No conoce tus políticas de devoluciones. No sabe cómo se llama el comercial de zona norte.
Lo que sí controlas completamente es lo que le metes en el contexto en el momento de la inferencia: el system prompt, el historial de conversación, los documentos que recuperas vía RAG, los resultados de las herramientas que ha llamado. Eso es todo el territorio del prompt engineering. Y es un territorio enorme.
La context window — el espacio máximo de texto que el modelo puede procesar de una vez — es el límite físico de ese territorio. Los modelos modernos tienen ventanas de 128.000, 200.000 o más tokens. Pero más ventana no significa que el modelo use todo de igual forma: tiende a prestar más atención al principio y al final, y a "perder" información enterrada en el centro. Diseñar el prompt es también decidir qué pones primero y por qué.
¿Cuáles son las técnicas de prompt engineering que realmente importan?
Hay decenas de técnicas con nombre. La mayoría comparten el mismo principio subyacente: cuanto más específico y bien estructurado es el input, más predecible y útil es el output. Estas son las que tienen impacto real:
¿Qué es el zero-shot prompting y cuándo basta solo?
El zero-shot prompting es preguntarle al modelo directamente, sin ejemplos, sin contexto adicional. "Resume este texto en tres puntos". "Clasifica este email como queja, consulta o felicitación". Es lo que hace la mayoría de gente sin saberlo.
Funciona cuando la tarea es suficientemente genérica como para estar bien representada en los datos de entrenamiento del modelo. Los LLMs modernos son asombrosamente buenos en zero-shot para tareas estándar: clasificación sencilla, resúmenes, traducciones, generación de código básico.
Donde falla es cuando la tarea requiere criterio específico de tu negocio. "Clasifica este ticket como urgente o no urgente" en zero-shot va a usar el criterio de urgencia que el modelo aprendió del training data — que probablemente no coincide con el tuyo. Ahí necesitas otra cosa.
También falla cuando el dominio es lo suficientemente especializado como para que el modelo no tenga buena cobertura en training: terminología legal muy concreta, jerga sectorial poco frecuente en internet, siglas internas de tu empresa. En esos casos el zero-shot produce respuestas genéricas que parecen correctas pero no lo son para tu contexto específico.
¿Qué aporta el few-shot prompting respecto a dar instrucciones?
El few-shot prompting es dar al modelo dos, tres, cinco ejemplos de input-output antes de hacerle la pregunta real. No le explicas la regla: le muestras la regla en acción.
Clasifica estos mensajes:
Mensaje: "Llevo tres días sin recibir mi pedido"
Clasificación: Urgente
Mensaje: "¿Cuál es el horario de la tienda?"
Clasificación: No urgente
Mensaje: "Me habéis cobrado dos veces"
Clasificación: Urgente
Mensaje: "¿Podéis enviarme el catálogo?"
Clasificación:El few-shot es especialmente potente cuando la tarea tiene criterios subjetivos o específicos de tu negocio que son difíciles de explicar en palabras pero fáciles de demostrar con ejemplos. En lugar de intentar definir "tono amable pero profesional", le muestras tres respuestas que tienen ese tono y el modelo aprende el patrón.
La limitación es que los ejemplos consumen tokens. En un agente con muchas herramientas y contexto de conversación largo, cada token que añades al prompt es un token que no puede usar para la respuesta. El few-shot es una inversión de contexto que hay que justificar.
¿Cuándo y cómo usar chain-of-thought?
El chain-of-thought (CoT) es pedirle al modelo que razone paso a paso antes de dar la respuesta final. En su forma más simple: añadir "piensa paso a paso" o "explica tu razonamiento antes de responder" al prompt.
¿Por qué funciona? Porque obliga al modelo a generar texto intermedio que actúa como "scratch pad" — un espacio donde puede trabajar el problema antes de comprometerse con una respuesta. Los LLMs cometen muchos menos errores en razonamiento cuando se les fuerza a externalizar los pasos.
Para un agente de atención al cliente, el CoT tiene un uso específico y valioso: cuando el agente tiene que tomar una decisión que depende de varias condiciones. En lugar de saltar directo a la respuesta, el agente razona: "el cliente tiene un plan premium, la incidencia lleva más de 48 horas abierta, y según la política de SLA esto califica para compensación — por tanto debo ofrecer X". Ese razonamiento explícito reduce los errores y, en muchos casos, te permite auditar por qué el agente tomó una decisión.
El CoT no es gratis: genera más tokens, lo que aumenta la latencia y el coste por conversación. Para tareas simples de clasificación o respuesta directa, añade ruido sin añadir valor. La decisión de usarlo debe ser consciente.
¿Qué es el role prompting y por qué no es solo "actúa como"?
El role prompting consiste en asignarle al modelo un rol o identidad antes de que responda. La versión naive es "actúa como un experto en X". Eso funciona medianamente, pero se queda corto.
El role prompting bien hecho no le dice al modelo *quién es*, sino *qué criterios debe usar* y *desde qué perspectiva*. La diferencia es esta:
Versión naive:
Eres un agente de soporte de una empresa de software.Versión con criterio:
Eres el agente de soporte de Acme Software. Tu prioridad es resolver el problema del cliente en la primera interacción siempre que sea posible. Cuando no puedas resolver algo directamente, explica exactamente los próximos pasos y quién lo gestionará. Nunca des información sobre plazos que no puedas garantizar. Usa un tono directo y sin jerga técnica salvo que el cliente la use primero.La segunda versión le da al modelo criterios de decisión — qué priorizar cuando hay ambigüedad — y restricciones explícitas — qué no hacer nunca. Eso es lo que distingue un role prompt que mejora el comportamiento de uno que no cambia nada.
¿Para qué sirve el structured output en un agente?
El structured output es indicarle al modelo que su respuesta debe seguir un formato específico — JSON, XML, una lista numerada con campos fijos — en lugar de texto libre. La mayoría de modelos modernos permiten forzarlo a nivel de API (OpenAI, Anthropic y Google tienen parámetros específicos para ello).
En un agente de producción, el structured output no es un capricho: es una necesidad. Si tu agente tiene que llamar a una herramienta, rellenar un campo del CRM o activar un workflow, necesitas que su output sea parseable sin intervención humana. Un agente que responde en texto libre a una pregunta es un chatbot; un agente que responde en JSON parseable es una pieza de tu infraestructura.
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
El structured output también reduce las alucinaciones en contextos estructurados: cuando le pides al modelo que rellene un esquema con campos definidos, tiene menos espacio para inventar.
Un ejemplo práctico: si tu agente necesita crear un resumen de conversación para guardarlo en el CRM al cerrar el ticket, el structured output te permite recibir siempre un JSON con los campos `motivo`, `resolución`, `sentiment` y `escalado`. Sin él, el modelo lo describe en prosa y tienes que parsearlo con heurísticas frágiles. Con él, la integración es directa y el dato llega limpio al sistema.
¿Qué tabla comparativa tienen las técnicas de prompt engineering?
Antes de entrar en la capa de agentes, una referencia rápida de cuándo usar cada técnica:
- Zero-shot — Mejor para: Tareas genéricas bien cubiertas en training · Coste en tokens: Bajo · Requiere ejemplos: No
- Few-shot — Mejor para: Tareas con criterio específico de negocio · Coste en tokens: Medio · Requiere ejemplos: Sí (2-10)
- Chain-of-thought — Mejor para: Decisiones con múltiples condiciones · Coste en tokens: Alto · Requiere ejemplos: Opcional
- Role prompting — Mejor para: Definir comportamiento base del agente · Coste en tokens: Bajo · Requiere ejemplos: No
- Structured output — Mejor para: Integración con sistemas, parseo de datos · Coste en tokens: Bajo · Requiere ejemplos: No
- Combinado CoT + few-shot — Mejor para: Tareas complejas con criterio específico · Coste en tokens: Alto · Requiere ejemplos: Sí
La combinación más habitual en producción es role prompting + few-shot + structured output: defines quién es el agente, le muestras cómo debe comportarse en los casos difíciles, y le fuerzas a responder en formato parseable. El chain-of-thought se activa selectivamente para las decisiones que lo justifican.
¿Cómo cambia el prompt engineering cuando el modelo tiene herramientas?
Aquí es donde la mayoría de tutoriales de prompt engineering se quedan cortos. Las técnicas anteriores aplican perfectamente cuando el modelo solo genera texto. Pero cuando el modelo puede llamar herramientas — buscar en una base de datos, consultar el CRM, enviar un email, hacer una reserva — el prompt engineering se complica de forma no obvia.
¿Qué decide el system prompt en un agente autónomo?
En un agente con herramientas, el system prompt es el documento más importante de toda la arquitectura. No es solo contexto: es la constitución del agente. Define quién es, qué puede hacer, qué no puede hacer nunca, cómo debe decidir cuando hay ambigüedad, y cómo debe comportarse cuando falla una herramienta.
Un system prompt bien diseñado para un agente de producción incluye al menos:
- Identidad y misión: Quién es el agente y cuál es su objetivo primario.
- Herramientas disponibles: No solo qué herramientas tiene, sino cuándo usarlas y cuándo no. Un agente sin criterio de uso de herramientas llama a todas en cada mensaje.
- Límites explícitos: Qué no puede hacer nunca (acceder a datos de terceros, modificar pedidos sin confirmación, comprometerse a precios fuera de tarifa).
- Comportamiento ante fallos: Qué hace cuando una herramienta devuelve error, cuando no encuentra información, cuando el cliente pide algo fuera de scope.
- Tono y restricciones de respuesta: Longitud máxima, idioma, nivel de tecnicidad.
El error más común que vemos en agentes en producción es un system prompt de tres líneas en un agente que tiene ocho herramientas y acceso a datos sensibles. La complejidad del system prompt debe ser proporcional a la complejidad del agente.
¿Qué son las tool descriptions y por qué importan tanto?
Cuando el modelo tiene herramientas disponibles, cada herramienta viene con una tool description — un texto que le explica al modelo qué hace esa herramienta, qué parámetros acepta y cuándo llamarla. Esas descriptions son, técnicamente, parte del prompt. Y son parte del prompt que casi nadie cuida.
Una tool description mal escrita produce dos tipos de problemas:
- El modelo llama la herramienta cuando no debe. Si la description no especifica las condiciones de uso, el modelo llama a la herramienta de "buscar en la base de conocimiento" para absolutamente todo, incluyendo preguntas que podría responder con conocimiento general.
- El modelo no llama la herramienta cuando sí debe. Si la description no cubre bien los casos de uso, el modelo ignora herramientas que tenía disponibles y improvisa en su lugar.
Una buena tool description incluye: qué hace la herramienta en una frase, en qué condiciones usarla, qué condiciones la excluyen (cuándo NO llamarla), y los parámetros con su tipo y descripción. Escribir tool descriptions es prompt engineering aplicado a la capa de herramientas, y tiene el mismo impacto en la calidad del agente que el system prompt.
El function calling — la implementación técnica del tool use en la API — está directamente condicionado por la calidad de esas descriptions. Dos agentes con las mismas herramientas y el mismo modelo pueden comportarse de forma radicalmente distinta si sus tool descriptions son distintas.
Un ejemplo concreto: imagina un agente con dos herramientas — `buscar_politica_devolucion` y `consultar_estado_pedido`. Si la tool description de la primera dice solo "busca información sobre devoluciones", el modelo la llamará también para preguntas sobre cambios, garantías y reclamaciones — situaciones para las que quizás no tienes información suficiente en esa fuente. Si la description dice "busca en la política de devoluciones estándar. Usar cuando el cliente pregunta sobre plazos, condiciones o excepciones de devolución de producto. No usar para reclamaciones de pago ni garantías extendidas", el modelo sabe exactamente cuándo activarla y cuándo no.
¿Cuántos pasos puede razonar un agente con un buen prompt?
Una pregunta que surge mucho cuando se empieza a trabajar con agentes: ¿cuántas acciones en cadena puede gestionar el modelo de forma fiable? La respuesta honesta es: depende del modelo, pero el prompt es el factor limitante antes que el modelo en la mayoría de los casos.
Un agente que necesita hacer tres pasos — consultar el estado del pedido, verificar si aplica la política de devolución express, y generar la respuesta con los pasos concretos — puede hacerlo con fiabilidad si el system prompt define claramente el orden de operaciones y los criterios de cada paso. Si el prompt no define ese flujo, el modelo toma atajos: salta pasos, combina acciones que no debería combinar, o responde antes de tener toda la información.
El razonamiento en cadena de un agente no lo da el modelo solo. Lo da el modelo más el prompt que lo estructura.
¿Cuándo el prompt engineering no es suficiente?
El prompt engineering tiene límites. Saber dónde están esos límites evita que pierdas semanas intentando resolver con prompts problemas que necesitan otra solución.
¿Cuándo necesitas RAG en lugar de más prompt?
El prompt engineering no puede darle al modelo información que no tiene. Si tu agente necesita responder con datos que cambian frecuentemente — el estado de un pedido, el saldo de una cuenta, las plazas disponibles en una agenda — no hay prompt que solucione eso. Necesitas RAG (Retrieval-Augmented Generation): un sistema que recupera la información actualizada en el momento de la consulta y se la pasa al modelo como contexto.
La señal de que necesitas RAG: el agente alucina respuestas que deberían venir de datos reales, o das respuestas desactualizadas porque el modelo solo sabe lo que sabía en el momento del training. El prompt no cambia eso; una arquitectura de RAG vs fine-tuning sí.
También necesitas RAG cuando el volumen de información que el agente debe manejar supera lo que cabe razonablemente en el context window. Un manual de 500 páginas no cabe en el prompt — pero sí puedes recuperar los tres fragmentos más relevantes para cada pregunta y pasárselos al modelo.
¿Cuándo necesitas fine-tuning en lugar de más prompt?
El fine-tuning es ajustar los pesos del modelo con ejemplos de tu dominio. Es una solución diferente a un problema diferente: no te da información nueva (eso es RAG), sino que cambia el comportamiento base del modelo.
Necesitas fine-tuning cuando:
- El modelo usa consistentemente una terminología o un estilo que no quieres y el prompt no es suficiente para corregirlo.
- El modelo comete siempre el mismo tipo de error en tu dominio específico (por ejemplo, malinterpreta sistemáticamente la jerga de tu sector).
- Tienes miles de ejemplos de input-output correctos y quieres "hornearlo" en el modelo para no tener que pasarlos como few-shot en cada llamada.
La mayoría de empresas no necesita fine-tuning todavía. El 80% de los problemas que parecen "el modelo no entiende nuestro dominio" se resuelven con un system prompt bien escrito, few-shot prompting y, si hay datos dinámicos, RAG. El fine-tuning es la artillería pesada: cara de entrenar, cara de mantener, y solo merece la pena cuando las opciones anteriores ya están bien implementadas y sigues teniendo el problema. Para tomar esa decisión con criterio, nuestra guía de RAG vs fine-tuning recorre los casos reales con un árbol de decisión concreto.
Hay una tercera opción que a veces se ignora: los modelos especializados. Algunos proveedores ofrecen modelos preentrenados para dominios concretos (legal, medicina, finanzas). Si tu caso de uso encaja en uno de esos dominios, puede ser más rápido y barato que el fine-tuning propio — aunque con menos control sobre el comportamiento específico de tu empresa.
¿Cuáles son los errores más comunes de prompt engineering en agentes reales?
Después de trabajar con decenas de agentes en producción, estos son los patrones de error que se repiten:
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Instrucciones ambiguas que el modelo resuelve con el peor caso posible. "Responde de forma profesional" es ambiguo. ¿Profesional quiere decir formal? ¿Directo? ¿Sin humor? El modelo elige. Y elige diferente cada vez. Las instrucciones que funcionan son específicas y medibles: "respuestas de máximo tres párrafos", "no uses saludos como 'Espero que te encuentres bien'", "usa el nombre del cliente si está disponible".
System prompt sin jerarquía de prioridades. Cuando hay instrucciones que pueden entrar en conflicto — "sé empático con el cliente" y "no prometas plazos que no puedes garantizar" — el modelo necesita saber cuál prevalece. Sin una jerarquía explícita, el modelo improvisa y el comportamiento es inconsistente.
Herramientas sin condiciones de salida. Definir cuándo llamar una herramienta sin definir cuándo dejar de usarla — o qué hacer si falla — produce agentes que entran en bucles o que simplemente se quedan bloqueados cuando el sistema externo devuelve un error.
Few-shot con ejemplos del mejor caso. Los ejemplos que le das al modelo tienden a mostrar la conversación ideal: cliente claro, pregunta sencilla, respuesta perfecta. El modelo aprende ese patrón. Cuando llega un cliente confuso, con un caso edge, o que mezcla dos problemas distintos en el mismo mensaje, el agente no sabe cómo manejarlo porque nunca lo ha "visto". Los ejemplos más valiosos para el few-shot son los casos difíciles, no los fáciles.
No testear con distribución real. El prompt perfecto para las preguntas que tú mismo escribes en la fase de desarrollo puede ser mediocre para las preguntas que hacen los clientes reales. Las dos distribuciones no son la misma. Sin un set de evaluación basado en conversaciones reales, estás optimizando para el wrong objective.
¿Cómo afecta el prompt engineering a la calidad de tu agente de atención al cliente?
Todo lo anterior es técnica. Esto es lo que significa en la práctica cuando tu agente habla con clientes reales.
Un agente de atención al cliente con IA tiene que gestionar, en la misma conversación, preguntas directas ("¿cuál es vuestro horario?"), problemas que requieren razonamiento ("me habéis cobrado dos veces pero solo tengo el cargo una vez en mi app"), situaciones de frustración del cliente, y casos que deben escalarse a un humano. Ese rango de situaciones necesita instrucciones distintas para cada tipo.
El prompt engineering en atención al cliente no es escribir respuestas bonitas. Es diseñar el criterio de decisión del agente para cada tipo de situación.
Algunos ejemplos concretos de lo que el prompt decide:
- ¿Cuándo escala el agente a un humano? Si el system prompt no lo define explícitamente, el agente escala demasiado (inseguro) o no escala nunca (temerario). Ninguno de los dos es aceptable.
- ¿Cómo maneja el agente la información que no tiene? Un agente sin instrucciones sobre esto improvisa — y un agente que improvisa sobre políticas de empresa es un riesgo legal y reputacional. El prompt debe definir exactamente qué hace el agente cuando no encuentra la respuesta.
- ¿Qué tono usa cuando el cliente está frustrado? El few-shot prompting con ejemplos de cómo gestionar situaciones de queja es más efectivo que cualquier instrucción en prosa sobre "ser empático".
- ¿Qué datos puede o no puede confirmar el agente? Sin restricciones explícitas en el prompt, el modelo tenderá a confirmar lo que el cliente dice aunque no tenga forma de verificarlo. Eso es un problema. Y cuando el agente necesita datos verificados sobre la empresa —políticas, precios, procedimientos—, la fuente que consulta es la base de conocimiento con IA: el prompt engineering y la base de conocimiento trabajan juntos, no son alternativas.
La diferencia entre un agente que las empresas confían para gestionar su soporte y uno que acaba siendo desconectado en dos semanas no está en el modelo que usan. Está en el trabajo que hay detrás de los prompts.
Un dato que vemos con frecuencia: el mismo modelo base, con el mismo conjunto de herramientas, puede pasar de un 40% de resolución autónoma a más del 70% simplemente con un system prompt bien diseñado, few-shot para los casos edge más frecuentes, y tool descriptions que definen los límites de cada herramienta. No es magia: es prompt engineering aplicado con criterio.
¿Cuál es el proceso de mejora del prompt en producción?
El prompt engineering no es un trabajo que se hace una vez. Es un proceso iterativo que combina criterio humano y datos reales.
El ciclo práctico:
- Define el comportamiento deseado en términos concretos. No "que sea útil", sino "que resuelva sin escalar el 70% de las consultas de tipo X" o "que nunca confirme un plazo de entrega sin consultarlo en el sistema".
- Crea un set de evaluación — una colección de conversaciones representativas con la respuesta correcta anotada. Sin esto, cualquier cambio en el prompt es un salto al vacío.
- Cambia una variable cada vez. Si cambias el system prompt, el few-shot y una tool description al mismo tiempo, no sabrás qué mejoró qué. El prompt engineering necesita el mismo rigor experimental que cualquier otra optimización de producto.
- Mide el impacto sobre el set de evaluación antes de llevar el cambio a producción. Herramientas como RAGAS o las capacidades de evaluación nativas de LLM-as-judge te permiten automatizar parte de esto.
- Monitoriza en producción. Las conversaciones reales siempre traen casos que no anticipaste. Un sistema de revisión de muestras de conversaciones — aunque sea manual al principio — es la fuente más valiosa de mejoras del prompt y no puede sustituirse con ninguna otra técnica.
El mayor error que vemos: equipos que lanzan el agente, ven que "funciona bien" en la demo, y lo dejan tal cual. El prompt que funciona en demos es el que sabe las preguntas de antemano. El prompt que funciona en producción es el que ha visto cientos de conversaciones reales y ha sido refinado con ellas.
Preguntas frecuentes sobre prompt engineering
¿El prompt engineering va a desaparecer con los modelos más avanzados?
No. Los modelos más avanzados necesitan instrucciones más precisas, no menos. Un modelo que razona mejor amplifica tanto los buenos prompts como los malos. La diferencia entre un prompt bien diseñado y uno mediocre se hace más visible, no menos, a medida que el modelo es más capaz.
¿Hace falta saber programar para hacer prompt engineering?
Para prompts básicos, no. Para prompt engineering de agentes en producción — diseñar system prompts, tool descriptions, evaluar con datos, integrar con RAG — hay una capa técnica que ayuda entender. Pero el núcleo de la disciplina — qué instrucciones dan el comportamiento deseado — es más lingüística y lógica que código.
¿Cuántos ejemplos necesito para el few-shot prompting?
Depende de la complejidad de la tarea. Para clasificaciones simples, tres o cinco ejemplos suelen ser suficientes. Para tareas con muchos matices, diez o quince. Más allá de veinte, el retorno marginal cae rápido y el coste de tokens sube. Si necesitas muchos más ejemplos para que el modelo aprenda el patrón, considera fine-tuning.
¿El chain-of-thought siempre mejora los resultados?
Para tareas de razonamiento complejo, casi siempre. Para tareas de clasificación simple o respuesta directa de hechos, a veces empeora — el modelo razona hacia la respuesta correcta y luego la cambia en el último paso. En la práctica: prueba con y sin CoT y mide.
¿Qué diferencia hay entre un prompt engineer y alguien que "sabe usar ChatGPT"?
El primero diseña prompts que funcionan en producción, de forma predecible, sobre una distribución de inputs que no ha visto antes. El segundo ha optimizado para las preguntas que él mismo hace. Son habilidades distintas.
¿El prompt engineering aplica solo a LLMs de texto?
No. Los principios de dar instrucciones precisas, contexto relevante y ejemplos aplican también a modelos multimodales (texto + imagen), modelos de código, y modelos especializados. La implementación cambia; la lógica de fondo no.
---
En GuruSup aplicamos estas técnicas — system prompts con criterio, few-shot para casos edge, chain-of-thought en decisiones complejas, tool descriptions precisas — en los agentes de IA que montamos para empresas que quieren que su soporte funcione sin depender de que un humano esté mirando. Si tu agente responde bien en la demo pero pierde pie con conversaciones reales, el problema casi siempre está en el prompt. Cuéntanos cómo lo tienes configurado.