AI Agent Architecture
Expert strategies to scale customer support with AI — without scaling your team.

What Is AI Automation? Complete Guide
AI automation combines machine learning with process automation to handle tasks that need judgment, not just rules. Here is how it works and where it matters.
Best AI Automation Tools 2026
AI automation tools fall into distinct categories. Here is how to navigate the landscape, compare platforms, and pick the right tool for your specific needs.
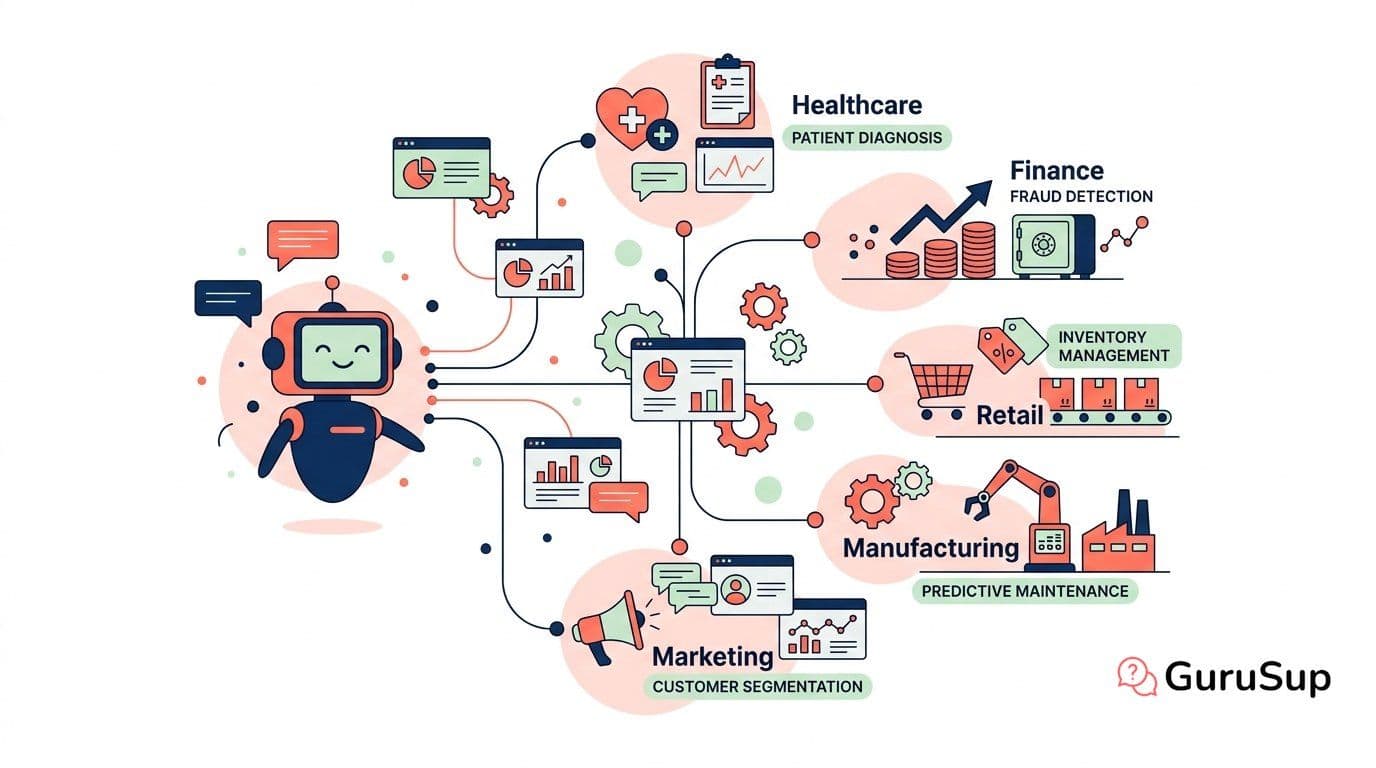
20 AI Automation Examples by Industry
20 real AI automation examples across five industries. What gets automated, what stays human, and what results companies are seeing.
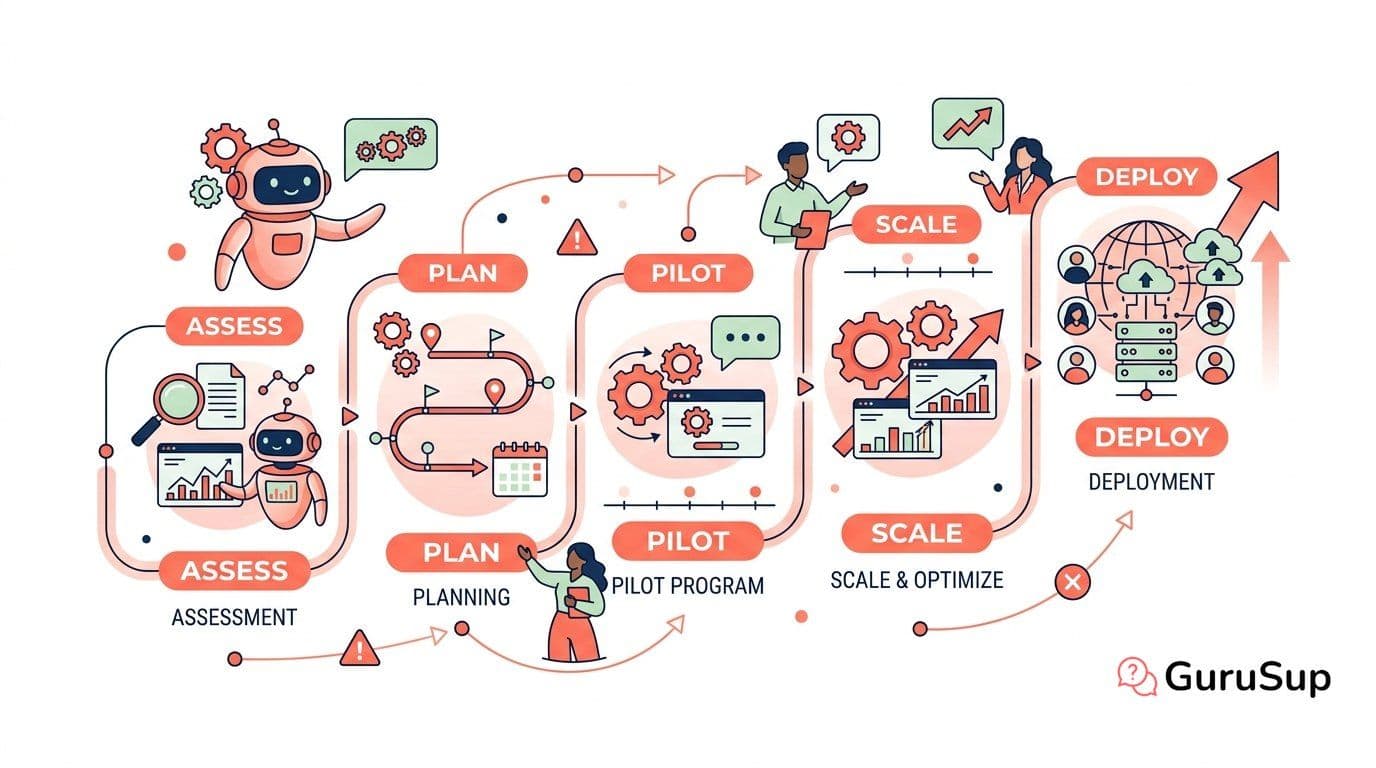
AI Automation Implementation Roadmap
A 5-phase roadmap for AI automation implementation. From assessment to enterprise-wide deployment, with timelines, change management, and mistakes to avoid.
ISO 42001: AI Management System Guide
Guía completa de ISO 42001 para sistemas de gestión de IA. Qué cubre, proceso de certificación, requisitos clave y alineación con el EU AI Act.
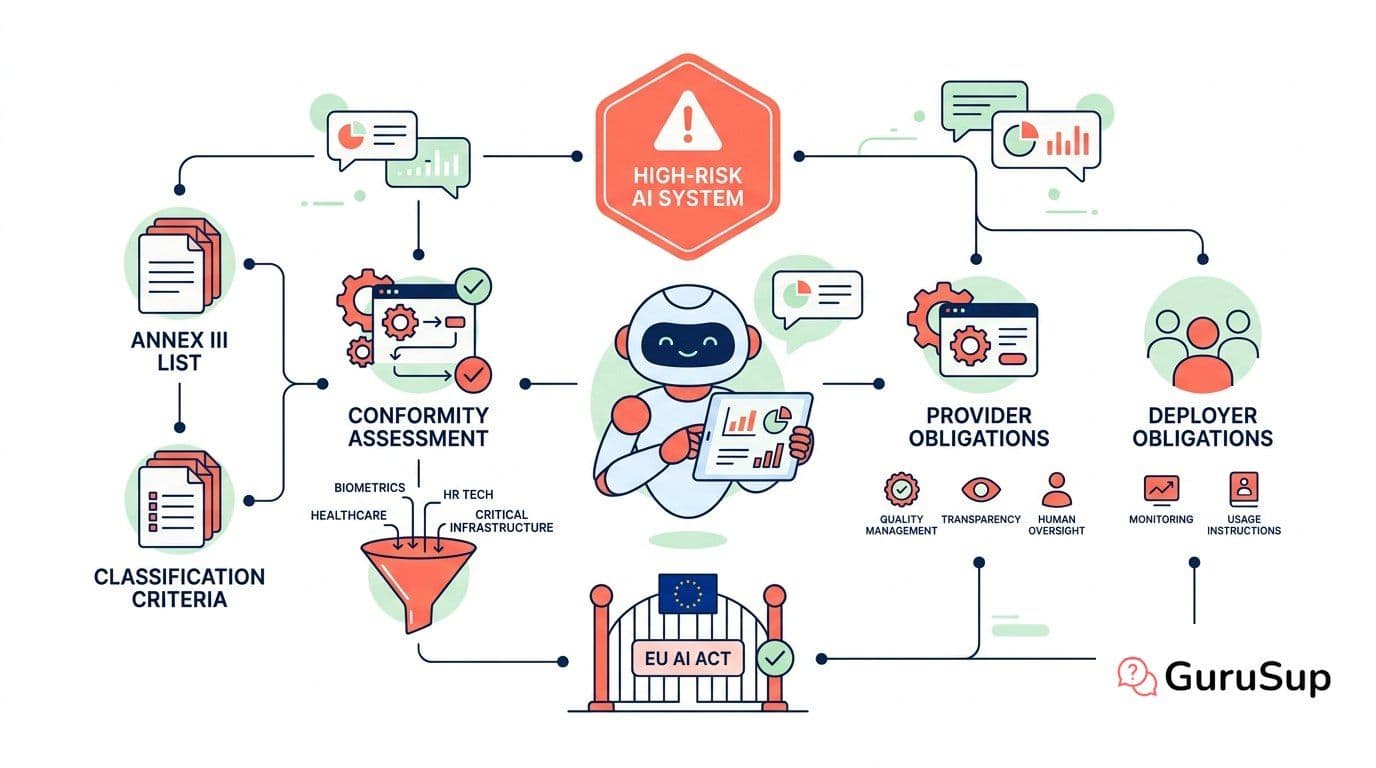
High-Risk AI Systems Under the EU AI Act
What qualifies as high-risk AI under the EU AI Act: the Annex III list, conformity assessment requirements, and obligations for providers and deployers.
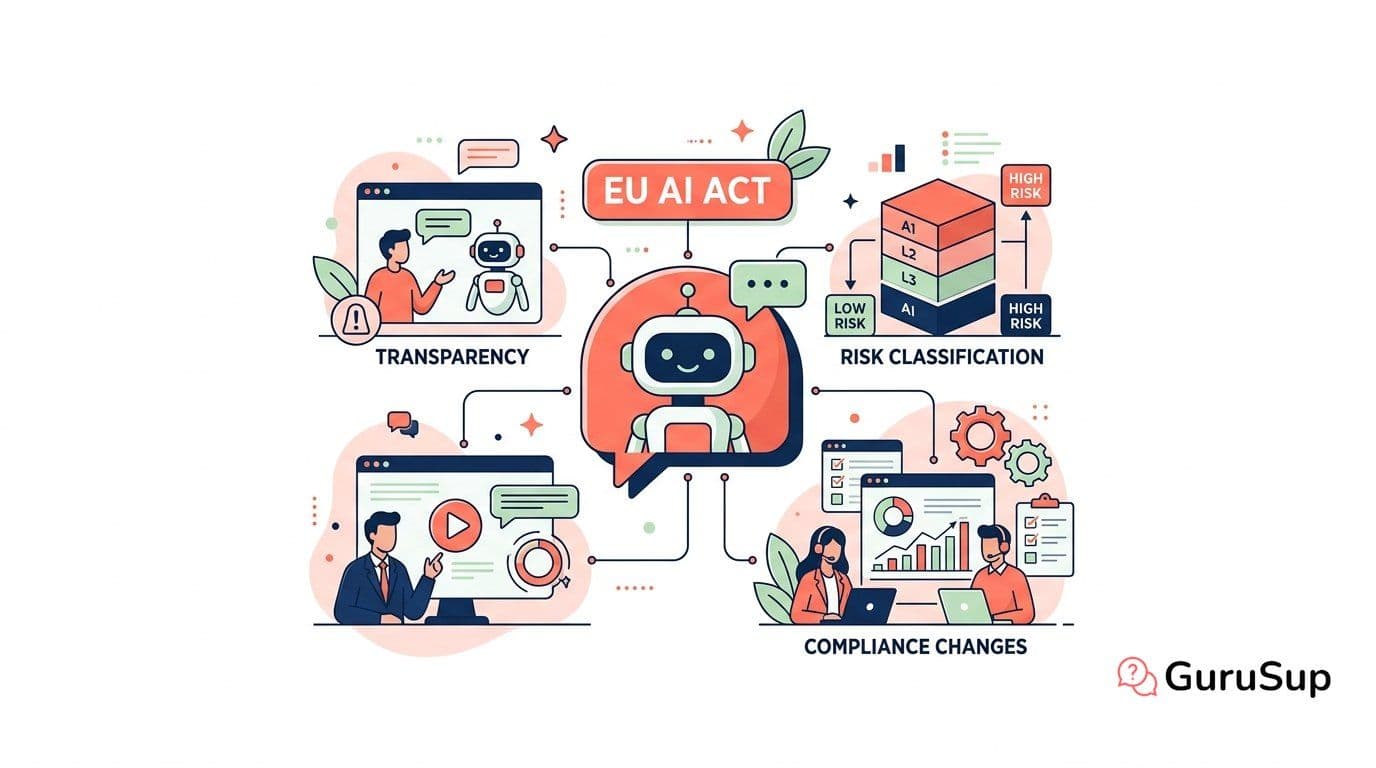
EU AI Act for Customer Support Teams
How the EU AI Act affects customer support chatbots and AI tools: transparency requirements, risk classification, and what support teams need to change.
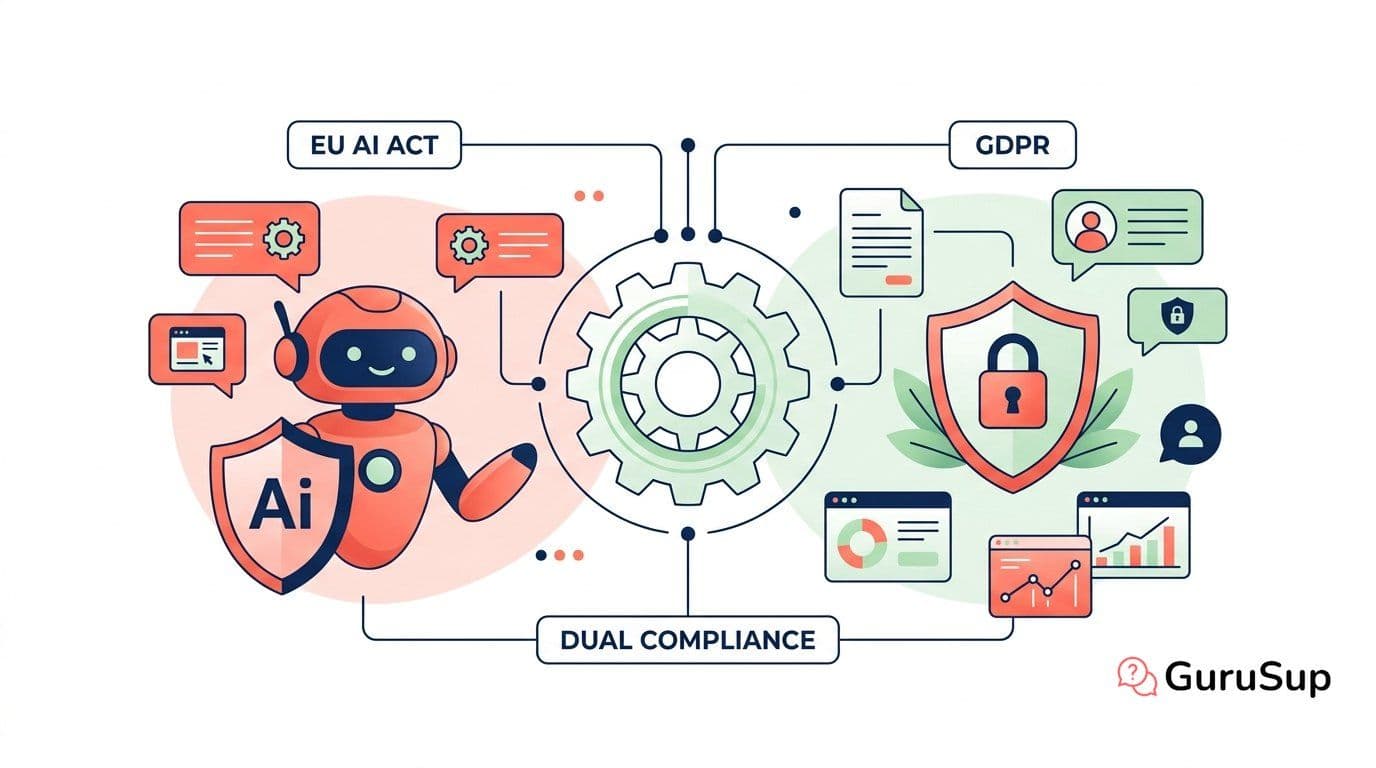
EU AI Act vs GDPR: How They Work Together
How the EU AI Act and GDPR interact: where they overlap, where they differ, and strategies for dual compliance when your AI processes personal data.
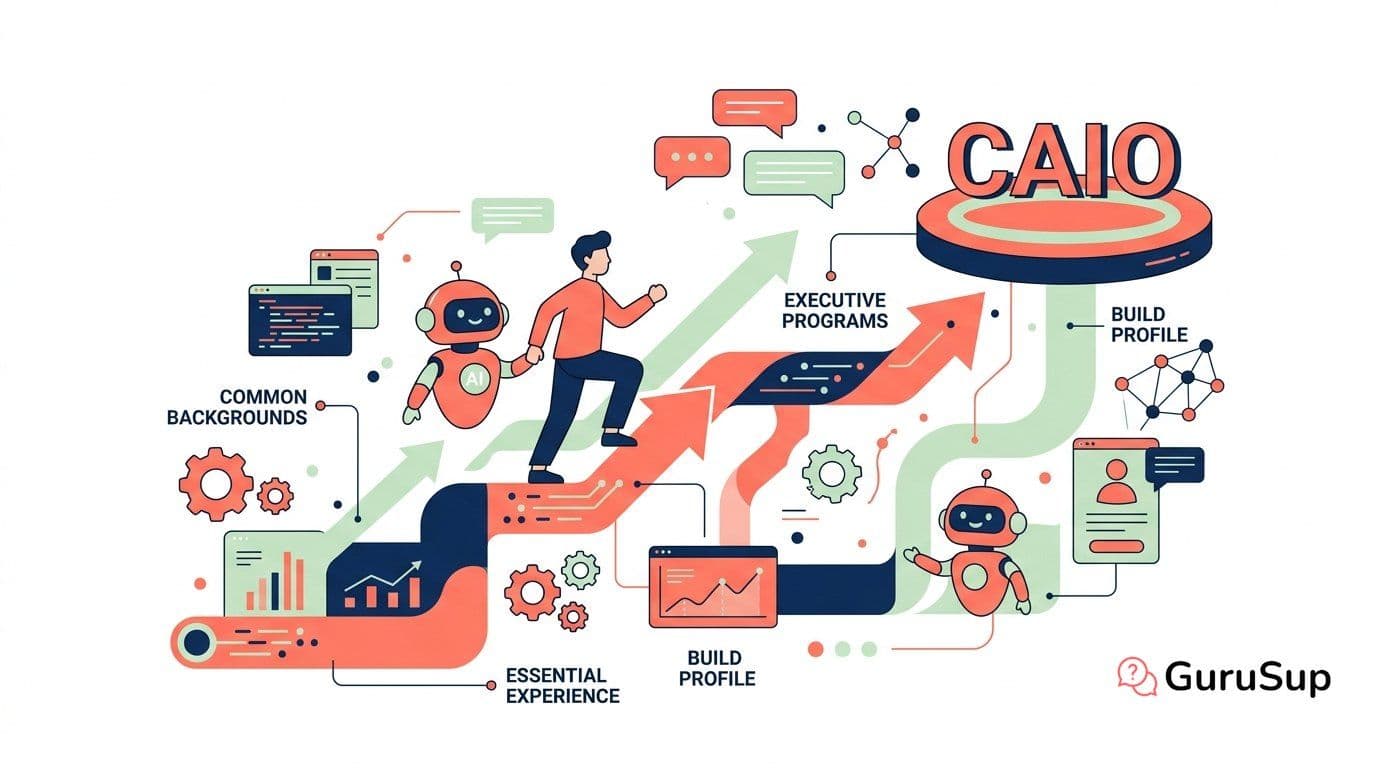
How to Become a Chief AI Officer
Career paths to the CAIO role: common backgrounds, essential experience, executive programs at Stanford and MIT, and how to build the right profile.