Agentic RAG: qué es y en qué se diferencia del RAG clásico
Qué es el agentic RAG, cómo funciona, en qué se diferencia del RAG clásico y sus variantes principales: Self-RAG, CRAG y GraphRAG. Con casos de negocio reales.
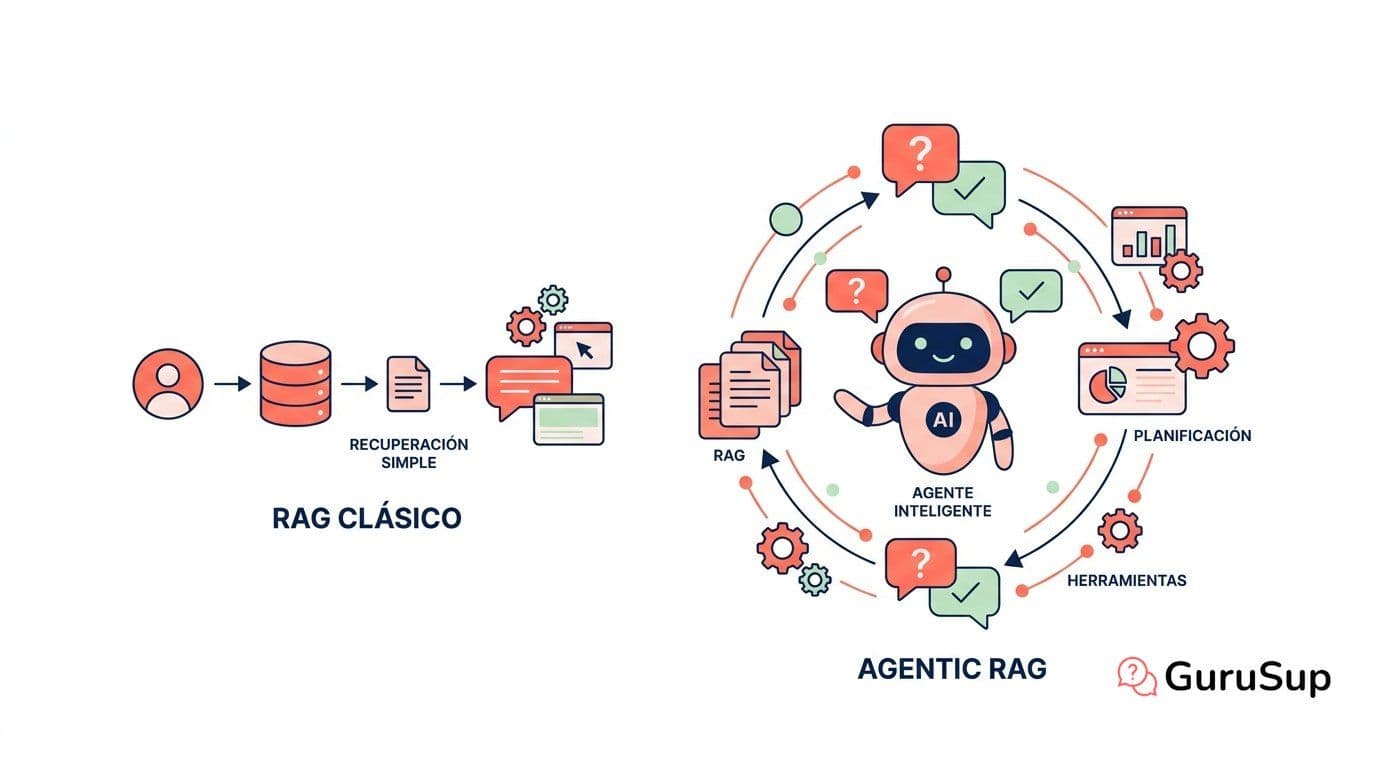
Tabla de contenidos
- ¿Qué es el agentic RAG?
- ¿Qué hace exactamente el agente en un sistema agentic RAG?
- ¿En qué se diferencia el agentic RAG del RAG clásico?
- ¿Cuáles son las variantes principales del agentic RAG?
- ¿Cómo funciona el routing y el multi-step retrieval?
- ¿Cuándo usar agentic RAG y cuándo no?
- ¿Qué implica el agentic RAG para la atención al cliente?
- ¿Qué relación tiene el agentic RAG con los agentes de IA?
- Preguntas frecuentes sobre agentic RAG
Llevas meses con tu sistema RAG funcionando. La base de conocimiento está cargada, los embeddings son correctos, el modelo es bueno. Y aun así, de vez en cuando te llega una pregunta de cliente con tres pasos —"¿puedo devolver el pedido si ya llegó a almacén, y cuánto tarda el reembolso al BBVA?"— y la respuesta sale incompleta, o mezcla información que no viene al caso, o directamente se inventa la política de devolución.
No es un problema de modelo. No es un problema de chunking. Es un problema de arquitectura: el RAG clásico recupera información una vez y genera. Punto. No puede darse cuenta de que lo que recuperó no era suficiente. No puede volver a buscar. No puede comprobar si lo que va a decir tiene sentido. Y en preguntas que necesitan varios pasos de razonamiento, ese límite se nota.
Ahí es exactamente donde entra el agentic RAG.
En GuruSup llevamos tiempo montando agentes de IA que atienden clientes sobre documentación real de empresas, y el salto de un RAG estático a uno agéntico es, en la práctica, el salto entre un sistema que a veces falla y uno que sabe cuándo no tiene suficiente información para responder bien.
¿Qué es el agentic RAG?
El agentic RAG es una arquitectura de IA en la que el retrieval —la parte de recuperar información— está controlado por un agente que razona, decide y puede actuar en bucles iterativos, en lugar de ejecutarse una sola vez de forma lineal.
En un RAG clásico el flujo es fijo: el usuario hace una pregunta, el sistema convierte esa pregunta en un vector, recupera los chunks más similares de la base de datos vectorial y el LLM genera una respuesta con ese contexto. Es un pipeline de un solo disparo: recupera una vez, genera una vez, fin.
En el agentic RAG, el LLM actúa como un agente con capacidad de decisión. Antes de responder, el agente evalúa si necesita recuperar información, qué fuente debe consultar, si lo que recuperó es suficiente o si tiene que reformular la consulta y volver a buscar. Si la primera recuperación no basta, el agente no genera una respuesta mediocre: itera. Puede hacer varias búsquedas, consultar diferentes fuentes, evaluar la calidad de lo que encontró y autocorregirse antes de dar una respuesta final.
La diferencia no es de rendimiento marginal. Es de lógica de control: en el RAG clásico el flujo de recuperación es estático y lo diseña un humano; en el agentic RAG, el agente decide autónomamente la secuencia de pasos en función de lo que va encontrando.
¿Qué hace exactamente el agente en un sistema agentic RAG?
El agente que controla el pipeline de agentic RAG tiene cuatro capacidades que el RAG clásico no tiene:
Decide si recuperar o no. Antes de lanzar una búsqueda, el agente evalúa si la pregunta ya puede responderse con el contexto que tiene o si necesita recuperar información adicional. En preguntas simples o de seguimiento de conversación, esto evita búsquedas innecesarias que añaden latencia y coste.
Reescribe la query antes de buscar (query rewriting). Si la pregunta del usuario es ambigua o está mal formulada, el agente la reformula en términos que maximicen la relevancia del retrieval. Esto es especialmente útil en atención al cliente, donde el usuario escribe "eso de la garantía" en lugar de "política de garantía extendida del producto X".
Evalúa lo que recuperó antes de generar. Una vez que el sistema devuelve los chunks, el agente puntúa su relevancia. Si el resultado no es suficientemente pertinente, no genera una respuesta a medias: reformula la búsqueda y vuelve a intentarlo.
Itera hasta tener suficiente contexto. El agente puede hacer varias rondas de retrieval, cada una refinando la anterior, hasta que determine que tiene la información necesaria para dar una respuesta correcta y completa. Este ciclo de "llamada LLM → uso de herramienta → evaluación → llamada LLM" es el corazón del agentic RAG.
Además, en arquitecturas más avanzadas el agente puede usar múltiples fuentes —una base de datos vectorial para documentación interna, una búsqueda web para preguntas en tiempo real, una base de datos SQL para datos transaccionales— y decidir cuál consultar en cada paso.
¿En qué se diferencia el agentic RAG del RAG clásico?
La diferencia más clara es dónde vive el control del flujo. En el RAG clásico, el control lo tiene el desarrollador que diseña el pipeline: el orden de los pasos es fijo y no cambia. En el agentic RAG, el control lo tiene el agente en tiempo de ejecución: el orden de los pasos emerge de lo que el agente va decidiendo.
- **Flujo de retrieval** — RAG clásico: Estático, un solo disparo · Agentic RAG: Dinámico, iterativo
- **Control del pipeline** — RAG clásico: Diseñado por el desarrollador · Agentic RAG: Decidido por el agente en runtime
- **Query rewriting** — RAG clásico: No · Agentic RAG: Sí, el agente reformula si hace falta
- **Evaluación de resultados** — RAG clásico: No · Agentic RAG: Sí, antes de generar
- **Múltiples fuentes** — RAG clásico: Una sola por consulta · Agentic RAG: Varias, elegidas por el agente
- **Autocorrección** — RAG clásico: No · Agentic RAG: Sí, itera si la primera búsqueda falla
- **Coste y latencia** — RAG clásico: Bajo · Agentic RAG: Mayor (más llamadas al LLM)
- **Preguntas que maneja bien** — RAG clásico: Simples, una fuente · Agentic RAG: Complejas, multi-paso, multi-fuente
La clave está en el último punto: el RAG clásico es perfectamente válido para preguntas directas que se responden con un documento. El agentic RAG existe para preguntas que requieren combinar información de varias fuentes, verificar lo recuperado o resolver ambigüedad antes de responder.
¿Cuáles son las variantes principales del agentic RAG?
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
La arquitectura agentic RAG no es una sola cosa. Hay varias variantes que resuelven problemas concretos de formas distintas, y entenderlas es útil para elegir la adecuada a cada caso.
¿Qué es Self-RAG?
Self-RAG (Self-Reflective Retrieval-Augmented Generation) es una variante en la que el propio LLM genera tokens especiales de critique durante el proceso de generación. Antes de decidir si recuperar y después de generar cada fragmento de respuesta, el modelo puntúa su propio output con etiquetas como "¿es necesario recuperar?", "¿el fragmento recuperado es relevante?", "¿la respuesta generada es fiel al contexto?".
La diferencia con el agentic RAG genérico es que en Self-RAG la lógica de evaluación está integrada en el propio proceso de generación del LLM, no en un agente externo. Esto lo hace más eficiente en términos de arquitectura, pero requiere modelos entrenados específicamente para emitir esos critique tokens.
¿Qué es CRAG (Corrective RAG)?
CRAG —Corrective Retrieval-Augmented Generation— introduce un evaluador explícito que puntúa los documentos recuperados antes de que lleguen al LLM. Si la puntuación es alta (el documento es relevante), el flujo sigue normal. Si la puntuación es baja o media, el sistema activa una búsqueda complementaria —normalmente web— para reforzar el contexto antes de generar.
El aporte de CRAG respecto al RAG clásico es añadir una capa de control de calidad sobre el retrieval: en lugar de pasarle al LLM lo que recuperó y esperar que lo use bien, CRAG filtra activamente los documentos pobres. En atención al cliente con IA, esto se traduce en respuestas más fiables cuando la base de conocimiento tiene lagunas: en lugar de generar con contexto insuficiente, el sistema busca más antes de responder.
¿Qué es GraphRAG?
GraphRAG es una arquitectura desarrollada por Microsoft Research que sustituye —o complementa— la base de datos vectorial por un grafo de conocimiento. En lugar de recuperar chunks de texto por similitud semántica, el sistema navega entidades y relaciones del grafo para encontrar respuestas.
La ventaja de GraphRAG sobre el RAG vectorial clásico aparece en preguntas que necesitan razonar sobre relaciones entre entidades —"¿qué productos han comprado los clientes que también compraron X?"— que un retrieval por similitud de texto no puede responder bien. El grafo codifica esas relaciones de forma explícita, y el agente puede navegar por ellas de forma estructurada.
La desventaja es la complejidad de construcción y mantenimiento del grafo. Para la mayoría de casos de empresa —responder sobre documentación interna, políticas, catálogos— el RAG vectorial con agentic control ya es suficiente. GraphRAG tiene más sentido en corpus muy grandes con muchas relaciones entre entidades.
¿Cómo funciona el routing y el multi-step retrieval?
Dos mecanismos concretos que distinguen una implementación agentic real de una básica: el routing y el multi-step retrieval.
El routing es la capacidad del agente de elegir qué fuente de datos consultar según la naturaleza de la pregunta. Si la pregunta es sobre política interna de empresa, consulta la base de datos vectorial con los documentos internos. Si necesita información actualizada en tiempo real, lanza una búsqueda web. Si la pregunta es transaccional —"¿cuántos pedidos tiene este cliente?"— consulta la base de datos SQL. El agente aprende a hacer ese routing a partir de la instrucción del sistema y del contexto de la conversación.
El multi-step retrieval es el proceso de encadenar varias búsquedas en secuencia, donde cada una refina o complementa la anterior. Una pregunta como "¿puedo cambiar mi suscripción si llevo menos de 30 días y el cargo ya está procesado?" puede requerir recuperar primero la política de cambios, luego las condiciones de cargo procesado, y finalmente sintetizar ambas. Un RAG clásico lanza una sola búsqueda y genera con lo que encuentre. El agentic RAG descompone la pregunta y hace retrieval paso a paso hasta tener la información completa.
Esto conecta directamente con el software de base de conocimiento: la calidad de las respuestas de un sistema agentic depende tanto de la arquitectura del agente como de la calidad y estructura del conocimiento que gestiona.
¿Cuándo usar agentic RAG y cuándo no?
El agentic RAG no es siempre la respuesta correcta. Tiene un coste real: más llamadas al LLM, más latencia, más complejidad de implementación y más superficie de error. Antes de añadir agencia a tu pipeline, comprueba si la necesitas.
Usa agentic RAG cuando:
- Las preguntas frecuentes de tus usuarios necesitan combinar información de más de una fuente o más de un documento.
- Tu base de conocimiento tiene lagunas y necesitas un mecanismo de escalado o búsqueda complementaria cuando no hay respuesta directa.
- Las consultas son ambiguas o mal formuladas y necesitas query rewriting sistemático.
- El dominio exige verificar la respuesta antes de darla —compliance, soporte técnico, contratos—.
No uses agentic RAG cuando:
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
- Las preguntas son simples y siempre tienen respuesta directa en un único documento.
- La latencia es crítica y no puedes permitirte múltiples rondas de retrieval.
- Tu corpus es pequeño y bien estructurado: un RAG clásico bien ajustado con buen chunking ya cubre el caso.
- Estás empezando: monta primero un RAG clásico que funcione, mide sus fallos reales, y añade agencia donde los números lo justifiquen.
El principio es el mismo que con el chunking: no subas de complejidad hasta que los datos te digan que lo necesitas.
¿Qué implica el agentic RAG para la atención al cliente?
La aplicación más directa del agentic RAG en empresa es la atención al cliente con IA. No porque sea el único caso de uso, sino porque es donde los límites del RAG clásico se notan más.
Un cliente que pregunta sobre una devolución con condiciones especiales, sobre el estado de su pedido más la política de cambios de talla, o sobre compatibilidad entre productos que se compraron en fechas distintas está haciendo una pregunta multi-paso que el RAG clásico no puede resolver bien con una sola búsqueda. El agente, en cambio, descompone la pregunta, recupera cada pieza de información por separado, evalúa si tiene todo lo necesario y solo entonces genera.
El resultado práctico es una diferencia visible en resolución en primer contacto. Un sistema de atención al cliente con IA construido sobre agentic RAG puede responder preguntas complejas sin necesidad de que el cliente reformule o que el agente escale al equipo humano. Y eso es exactamente lo que marca la diferencia entre un chatbot de IA que ayuda de verdad y uno que frustra.
Lo que hemos visto al implementarlo en entornos reales es que el agentic RAG no elimina los errores, pero cambia su naturaleza: en lugar de dar una respuesta incorrecta con seguridad, el sistema tiene mecanismos para detectar que no tiene suficiente información y actuar en consecuencia. Esa diferencia —entre fallar en silencio y fallar de forma controlada— es la que hace que se pueda desplegar con confianza en producción.
¿Qué relación tiene el agentic RAG con los agentes de IA?
El agentic RAG no es un tipo de agente de IA: es una forma de construir el retrieval dentro de un sistema agéntico. Dicho de otro modo, el agentic RAG es la parte de recuperación de información de un agente de IA más amplio.
Un agente de IA puede hacer muchas cosas —consultar APIs, ejecutar código, gestionar tareas, enviar mensajes— y cuando necesita consultar información de una base de conocimiento, lo hace a través de un mecanismo de retrieval. Si ese mecanismo es agéntico —iterativo, con evaluación, con query rewriting— estamos hablando de agentic RAG. Si es estático, es RAG clásico dentro de un agente.
La distinción importa porque hay una tendencia a usar "agentic RAG" y "agente de IA" como sinónimos, y no lo son. El agentic RAG es una arquitectura de retrieval; los agentes de IA son sistemas que pueden actuar sobre el entorno. El retrieval agéntico es una de las herramientas que un agente usa, no el agente en sí.
Entender qué es RAG y cómo funciona el pipeline de recuperación es el punto de partida obligado antes de añadir la capa agéntica.
Preguntas frecuentes sobre agentic RAG
¿Qué es un agentic RAG? El agentic RAG es una arquitectura de recuperación de información en la que un agente de IA controla el proceso de retrieval de forma iterativa: decide si recuperar, reformula la query, evalúa los resultados y repite hasta tener contexto suficiente para generar una respuesta correcta. A diferencia del RAG clásico, el flujo no es fijo sino dinámico.
¿En qué se diferencia el agentic RAG del RAG clásico? El RAG clásico ejecuta una sola búsqueda y genera con el resultado, sin evaluar si lo recuperado es suficiente. El agentic RAG añade un agente que controla el flujo: puede hacer varias rondas de retrieval, reescribir queries, consultar múltiples fuentes y autocorregirse antes de responder.
¿Qué es Self-RAG? Self-RAG es una variante del agentic RAG en la que el LLM genera tokens especiales de critique durante la generación para evaluar si necesita recuperar información y si lo que recuperó es relevante y fiel. La lógica de evaluación está integrada en el modelo, no en un agente externo.
¿Qué es CRAG o Corrective RAG? CRAG añade un evaluador explícito que puntúa los documentos recuperados antes de pasarlos al LLM. Si la puntuación es baja, activa una búsqueda complementaria —normalmente web— antes de generar. Es especialmente útil cuando la base de conocimiento tiene lagunas.
¿Qué es GraphRAG? GraphRAG, desarrollado por Microsoft Research, sustituye o complementa la base de datos vectorial por un grafo de conocimiento. En lugar de recuperar por similitud semántica, el agente navega entidades y relaciones del grafo. Brilla en preguntas que requieren razonar sobre relaciones entre entidades.
¿Cuándo no usar agentic RAG? Cuando las preguntas son simples y tienen respuesta directa en un documento, cuando la latencia es crítica, o cuando empiezas: monta primero un RAG clásico que funcione, mide sus fallos reales y añade agencia solo donde los datos lo justifiquen.
---
Si tu sistema RAG actual resuelve bien las preguntas simples pero falla en las consultas de varios pasos, el salto al agentic RAG tiene sentido. En GuruSup montamos ese pipeline completo —retrieval iterativo, routing, evaluación y autocorrección— dentro de los agentes de IA que usamos para atender clientes sobre la documentación real de cada empresa. Si te interesa ver cómo funciona aplicado a tu caso, en nuestro software de base de conocimiento con IA puedes ver cómo lo hacemos.