Memoria en agentes de IA: tipos y cómo funciona
Qué es la memoria en los agentes de IA, cuáles son sus tipos (corto plazo, largo plazo, episódica, semántica, procedural), cómo se implementa con vector stores, LangGraph o mem0, y cómo cambia la atención al cliente.
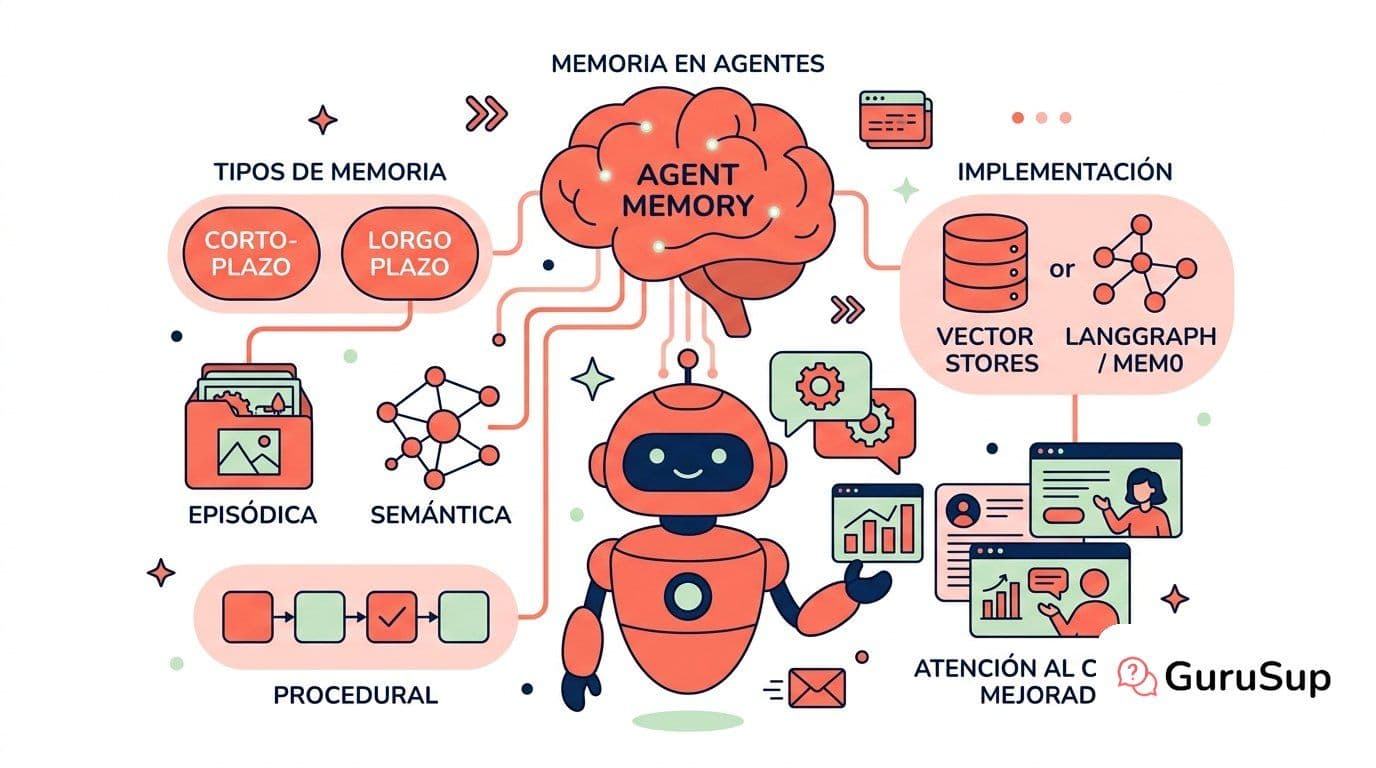
Tabla de contenidos
- ¿Qué es la memoria en un agente de IA?
- ¿Por qué un agente sin memoria falla en producción?
- Los tipos de memoria en los agentes de IA
- Cómo se implementa la memoria: de la teoría a la producción
- ¿Cuándo NO necesitas todos los tipos de memoria?
- La memoria en la atención al cliente: de la demo al caso real
- Gestión del contexto en sistemas multiagente
- Preguntas frecuentes sobre memoria en agentes de IA
- De un agente que olvida a uno que aprende
Tu agente de atención al cliente acaba de terminar una conversación con María. María ha explicado tres veces que su empresa tiene 45 empleados, que trabaja con Salesforce y que ya probó otra herramienta que no integró bien. El agente respondió de forma correcta en cada turno. Cuatro días después, María vuelve con una duda de seguimiento. El agente le pregunta: "¿Cuál es tu empresa y qué herramientas usáis?"
Ahí es cuando la IA, por muy sofisticada que sea, deja de parecer inteligente y empieza a parecer una llamada de teleoperadora.
Lo que falta no es más potencia de modelo. Lo que falta es memoria.
En GuruSup llevamos tiempo construyendo agentes de IA que atienden a clientes reales, y si algo hemos aprendido es que la memoria es la diferencia entre un agente que impresiona en la demo y uno que transforma cómo trabaja una empresa. En este artículo te cuento qué es exactamente la memoria en los agentes de IA, cuáles son sus tipos, cómo se implementa de verdad —con vector stores, LangGraph, mem0— y por qué todo esto cambia por completo el trabajo de atención al cliente con IA.
¿Qué es la memoria en un agente de IA?
Un agente de IA sin memoria es, técnicamente, un sistema sin estado (stateless). Cada llamada al modelo empieza de cero. No hay continuidad entre conversaciones, no hay aprendizaje acumulado, no hay noción de "lo que pasó antes". El modelo procesa lo que entra en su context window en ese momento y ya.
Eso funciona para tareas puntuales y aisladas. Pero en cuanto el agente necesita mantener una conversación coherente, personalizar respuestas según el historial del usuario o aprender de errores pasados, el modelo sin memoria se convierte en un problema.
La memoria en los agentes de IA es el conjunto de mecanismos que permiten al agente almacenar, recuperar y utilizar información más allá del contexto inmediato de una sola llamada. No es una sola cosa: es una arquitectura compuesta por capas con propósitos distintos, horizontes temporales distintos y tecnologías de implementación distintas.
El paper Cognitive Architectures for Language Agents (CoALA) del equipo de Princeton (2023) es la referencia académica más citada en este campo, y categoriza la memoria de los agentes tomando prestada la taxonomía de la psicología cognitiva humana. No es una metáfora: los tipos de memoria que describen tienen equivalentes directos en cómo funcionan los sistemas de IA modernos.
¿Por qué un agente sin memoria falla en producción?
Antes de entrar en los tipos, hay que entender el problema de raíz.
El límite del context window no es el único problema
Todos los LLM tienen un context window: la cantidad máxima de texto (tokens) que pueden procesar en una sola llamada. Los modelos actuales llegan a 128.000 o incluso 200.000 tokens, que suenan a mucho. Y lo son, para una conversación puntual.
El problema es doble. Primero, meter más contexto tiene un coste económico y de latencia: más tokens = más tiempo de respuesta y más gasto por llamada. Segundo, y más importante, existe el fenómeno documentado como "lost in the middle": los LLM tienden a prestar menos atención a la información que aparece en el centro de un contexto largo. Puedes meter toda la historia del cliente en el prompt y el modelo seguirá ignorando detalles críticos que aparezcan en el párrafo 47.
El resultado práctico: llenar el context window no es lo mismo que tener memoria.
El coste de empezar desde cero en cada sesión
Cuando un cliente vuelve después de días o semanas, el agente que no tiene memoria a largo plazo le recibe como si fuera la primera vez. El cliente tiene que repetir su contexto, sus preferencias, sus problemas ya resueltos. Eso es frustrante para el usuario y, desde el punto de vista de negocio, es tiempo de agente humano gastado en recopilación de información que ya estaba disponible.
En sectores como el legal, el médico o la gestión empresarial, donde el contexto histórico es crítico para tomar decisiones correctas, un agente sin memoria no solo es ineficiente: puede ser directamente peligroso.
Los tipos de memoria en los agentes de IA
La taxonomía estándar distingue cinco tipos. Los dos primeros (corto y largo plazo) son el eje temporal. Los tres siguientes (episódica, semántica, procedimental) son subtipos de la memoria a largo plazo con propósitos distintos.
Memoria a corto plazo: el contexto de la conversación actual
La memoria a corto plazo (short-term memory, STM) contiene la información de la sesión en curso. Es el historial de mensajes del chat: lo que el usuario dijo en el turno anterior, lo que respondió el agente, las decisiones tomadas dentro de la misma conversación.
Técnicamente, en la mayoría de implementaciones no es más que el array de mensajes que se pasa al LLM en cada llamada. Cada turno se añade al historial. El agente "recuerda" gracias a que toda esa secuencia forma parte de su contexto.
El límite obvio: cuando la conversación es muy larga, el historial empieza a presionar contra el context window. Hay tres estrategias habituales para gestionar esto:
Truncado por ventana deslizante: se mantienen solo los últimos N mensajes y se descartan los más antiguos. Sencillo, barato, pero arriesgas perder información que sigue siendo relevante.
Resúmenes progresivos: en lugar de descartar mensajes, el agente va generando resúmenes del historial acumulado y los sustituye en el contexto. Conservas la esencia de lo que pasó sin el coste de tokens de los mensajes completos. LangChain implementa esto con `ConversationSummaryMemory`.
Memoria operativa selectiva: en lugar de pasar todo el historial, un componente del sistema extrae solo la información más relevante para el turno actual. Es más sofisticado, pero produce resultados mucho mejores en conversaciones largas y técnicas.
La memoria a corto plazo es volátil: cuando la sesión termina, desaparece salvo que se persista explícitamente. Ese es el puente hacia el siguiente tipo.
Memoria a largo plazo: lo que persiste entre sesiones
La memoria a largo plazo (long-term memory, LTM) almacena información que debe sobrevivir más allá de una sola conversación. Es lo que permite que el agente recuerde que María tiene 45 empleados, que usa Salesforce y que ya probó otra herramienta, aunque hayan pasado cuatro días desde la primera conversación.
La LTM no vive en el modelo: vive fuera, en sistemas de almacenamiento persistente. El agente la consulta activamente cuando la necesita, en lugar de tenerla siempre en el contexto. Esto resuelve el problema del context window: no necesitas meter todo el historial de María en cada prompt; buscas solo lo relevante para la consulta actual.
Las tecnologías de implementación más habituales:
Vector stores / bases de datos vectoriales: Los recuerdos se convierten en embeddings y se almacenan en bases de datos como Pinecone, Weaviate, Qdrant o pgvector. Cuando el agente necesita recuperar información, calcula el embedding de la consulta actual y busca los recuerdos más similares semánticamente. Es el sistema más flexible para información no estructurada y conversacional. Profundizamos en cómo funcionan estas bases en nuestro artículo sobre sistemas multiagente con IA.
Bases de datos estructuradas (SQL): Para información muy concreta y bien definida —preferencias del usuario, historial de compras, datos de empresa— las bases SQL (PostgreSQL, SQLite) ofrecen consultas precisas y son más sencillas de mantener. El límite es que no funcionan bien para búsqueda semántica.
Knowledge graphs: Sistemas como Neo4j almacenan entidades y relaciones entre ellas. Permiten razonamiento más complejo ("¿qué clientes han tenido el mismo problema que María?") pero son más costosos de mantener.
Sistemas híbridos: En producción, los mejores sistemas combinan búsqueda vectorial (semántica) con búsqueda léxica (BM25) y bases estructuradas, cada una para el tipo de información que gestiona mejor.
Memoria episódica: el registro de lo que ha pasado
Dentro de la memoria a largo plazo, la memoria episódica almacena eventos específicos, secuencias de acciones y sus resultados. Es el "diario" del agente: qué hizo, qué funcionó, qué falló.
El nombre viene de la psicología cognitiva, donde la memoria episódica es la que te permite recordar experiencias concretas ("la vez que intenté hacer esa reserva y no había disponibilidad"). En IA, el uso más directo es el few-shot learning contextual: cuando el agente se enfrenta a una situación nueva, recupera episodios pasados parecidos y los usa como ejemplos para guiar su respuesta.
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
En la práctica, la memoria episódica se implementa como un registro estructurado de interacciones: qué entró, qué hizo el agente, qué salió, si el resultado fue satisfactorio o no. Algunos sistemas añaden valoraciones humanas o señales de feedback del usuario para marcar qué episodios fueron buenos y cuáles no.
Un caso de uso concreto: un agente de IA para atención al cliente que, al enfrentarse a una reclamación de facturación que no reconoce el patrón inmediatamente, recupera episodios pasados similares y adapta su respuesta basándose en cómo se resolvieron. Sin necesidad de reentrenar el modelo.
Memoria semántica: el conocimiento estructurado del dominio
La memoria semántica almacena hechos, conceptos y conocimiento general sobre el dominio. No es "lo que pasó" (eso es episódica), sino "lo que es": definiciones, reglas de negocio, información de producto, preferencias del usuario acumuladas.
En términos de implementación, la memoria semántica suele ser la base de conocimiento que se alimenta mediante RAG. Los documentos de la empresa, los manuales de producto, las políticas de devolución, los precios: todo eso es memoria semántica externalizada. Si quieres profundizar en cómo funciona RAG para alimentar esta capa, en nuestro artículo sobre qué es LangGraph tienes el detalle técnico.
Pero la memoria semántica también incluye el perfil acumulado del usuario: qué le gusta, qué no le gusta, qué ha comprado, qué problemas ha tenido. Estos "hechos sobre el usuario" se van acumulando en la memoria a largo plazo y el agente los recupera para personalizar sus respuestas.
La diferencia entre memoria episódica y semántica puede sonar sutil pero tiene implicaciones prácticas claras:
- "María intentó integrarse con Hubspot en septiembre y falló" → episódica
- "María prefiere comunicaciones por email, no por WhatsApp" → semántica
- "María es responsable de IT en una empresa de 45 personas del sector retail" → semántica
El agente necesita ambas para dar respuestas verdaderamente contextualizadas.
Memoria procedimental: cómo hace lo que hace
La memoria procedimental almacena las reglas, habilidades e instrucciones que definen el comportamiento del agente. En humanos, la analogía es saber montar en bici: no piensas en cada movimiento, lo ejecutas de forma automática porque el procedimiento está interiorizado.
En los agentes de IA, la memoria procedimental es, en la práctica, el system prompt y las instrucciones que definen su comportamiento base. Pero hay una variante más avanzada y más interesante: el metaprompting o reflexión.
En el metaprompting, el agente puede actualizar sus propias instrucciones basándose en lo que aprende de las interacciones. Si un agente descubre repetidamente que cierto tipo de pregunta requiere un paso adicional de verificación, puede refinar sus instrucciones para incluir ese paso automáticamente en el futuro. No es fine-tuning (no cambia los pesos del modelo), pero sí es una forma de aprendizaje que persiste.
Este tipo de memoria es el más relacionado con la capacidad de mejora autónoma del agente: un sistema que no solo recuerda qué hizo, sino cómo hacerlo mejor la próxima vez.
Cómo se implementa la memoria: de la teoría a la producción
Conocer los tipos es el qué. La implementación es el cómo. Y aquí es donde la mayoría de artículos se quedan cortos.
Context engineering: diseñar qué entra al LLM
El context engineering es la disciplina que decide qué información se incluye en el prompt de cada llamada al LLM. No es prompt engineering (que se centra en la redacción de instrucciones); es arquitectura de información: qué memorias recuperar, en qué orden presentarlas, cuántos tokens dedicar a cada tipo.
Un sistema de memoria bien diseñado no vuelca todo el historial en el contexto. Construye el contexto de forma dinámica, eligiendo qué piezas de memoria son más relevantes para la consulta actual. Esto requiere:
- Un mecanismo de recuperación que identifique las memorias más relevantes (búsqueda vectorial, filtros por metadatos, búsqueda híbrida)
- Un mecanismo de ranking que priorice cuando hay demasiadas memorias candidatas
- Un mecanismo de compresión que adapte la información al espacio disponible en el context window
El resultado es un prompt dinámico que contiene justo lo que el agente necesita saber en ese momento, sin desperdiciar tokens en información irrelevante.
LangGraph: state y checkpointing
LangGraph es actualmente el framework más utilizado para construir agentes de IA con estado persistente. Su contribución clave al problema de la memoria es doble: el state y el checkpointing.
El state en LangGraph es un objeto tipado que acompaña al agente durante toda su ejecución. No es solo el historial de mensajes: puede incluir variables de contexto, resultados de herramientas, decisiones tomadas, preferencias del usuario. Cada nodo del grafo puede leer el state y modificarlo. El state es la memoria operativa del agente mientras ejecuta una tarea.
El checkpointing es el mecanismo por el que el state se persiste entre sesiones. LangGraph tiene un sistema de checkpointers que guarda el state en cada paso de la ejecución. Cuando una conversación se reanuda, el checkpointer recupera el último state guardado y el agente continúa exactamente donde lo dejó. Esto es especialmente potente para tareas largas y multi-paso: si la ejecución se interrumpe (por timeout, error de red, o simplemente porque el usuario cerró la pestaña), el agente puede reanudarla sin perder el progreso.
Los checkpointers de LangGraph pueden configurarse con distintos backends: en memoria (para desarrollo), SQLite (para casos sencillos), PostgreSQL o Redis (para producción a escala).
Mem0: memoria persistente como servicio
Mem0 es una de las herramientas más interesantes que han aparecido en este espacio. Su propuesta es simple: añadir una capa de memoria persistente inteligente encima de cualquier LLM o framework de agentes, sin que tengas que construirla desde cero.
Mem0 funciona con un pipeline en dos fases. Primero, extracción: cuando se añaden mensajes al hilo del agente, Mem0 los procesa con un LLM para identificar qué información merece ser guardada como recuerdo (datos del usuario, preferencias, hechos importantes). Segundo, actualización: Mem0 decide si la nueva información debe añadirse como recuerdo nuevo, modificar uno existente o eliminar uno que ya no es válido.
El almacenamiento es híbrido: base de datos vectorial (para búsqueda semántica), base de datos de grafos (para relaciones entre entidades) y almacenamiento clave-valor (para acceso rápido a datos estructurados). Cuando el agente necesita contexto, Mem0 recupera los recuerdos más relevantes y los inyecta en el prompt.
La ventaja práctica de mem0 es que resuelve un problema difícil —decidir qué vale la pena recordar— de forma automatizada. Sin mem0, tienes que diseñar tú ese sistema de extracción y consolidación. Con mem0, lo tienes listo con unas pocas líneas de configuración.
Vector stores: la columna vertebral de la memoria a largo plazo
Los vector stores (bases de datos vectoriales) son la tecnología de almacenamiento más utilizada para la memoria a largo plazo en agentes. El principio es elegante: convertir los recuerdos en vectores numéricos (embeddings) que capturan el significado semántico, y almacenarlos de forma que puedas buscar "lo más similar a esta consulta" en milisegundos.
La búsqueda vectorial tiene una propiedad que las bases de datos tradicionales no tienen: funciona por similitud semántica, no por coincidencia exacta de palabras. Si María preguntó hace tres semanas sobre "integración con CRM" y ahora pregunta sobre "conectar con Salesforce", la búsqueda vectorial los relaciona aunque las palabras sean distintas.
Para la memoria de agentes, el proceso es:
- Ingesta: cuando se genera un recuerdo (una preferencia, un hecho, el resumen de una conversación), se convierte en un embedding y se almacena junto a sus metadatos (usuario, fecha, tipo de recuerdo, sesión de origen)
- Recuperación: antes de cada respuesta, el sistema calcula el embedding de la consulta actual y busca los recuerdos más cercanos en el espacio vectorial
- Filtrado: los metadatos permiten filtrar por usuario, fecha, tipo de recuerdo, para no mezclar la memoria de María con la de Pedro
- Inyección: los recuerdos recuperados se añaden al contexto antes de llamar al LLM
Los sistemas más robustos combinan búsqueda vectorial con filtros léxicos (BM25) para casos donde la precisión exacta importa más que la similitud semántica.
¿Cuándo y cómo se forman los recuerdos?
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Una pregunta que pocas guías responden bien: ¿cuándo se escribe un recuerdo? Hay dos estrategias con trade-offs distintos.
Escritura en tiempo real: el agente extrae y guarda recuerdos durante la conversación, en cada turno o al final de cada respuesta. La ventaja es la inmediatez: si el usuario menciona una preferencia en el turno 3, está disponible en el turno 5. El coste es latencia adicional en cada respuesta y mayor complejidad en el flujo principal.
Escritura en background: la generación de recuerdos ocurre como tarea asíncrona, separada del flujo principal de la conversación. La respuesta al usuario no espera a que los recuerdos se guarden. La latencia del agente no se ve afectada, pero los recuerdos generados en una conversación no están disponibles hasta que el proceso background termina.
En producción, la mayoría de sistemas sofisticados usan escritura en background para recuerdos de largo plazo (que no se necesitan inmediatamente) y escritura síncrona para actualizaciones de estado críticas (como "el usuario ha confirmado que quiere el plan premium").
¿Cuándo NO necesitas todos los tipos de memoria?
La respuesta honesta es que no todos los agentes necesitan los cinco tipos. Implementar memoria a largo plazo con vector stores, LangGraph checkpointing y mem0 tiene un coste real: tiempo de desarrollo, coste de infraestructura, complejidad operativa.
No necesitas memoria a largo plazo si: tu agente gestiona tareas completamente independientes entre sí, sin historial de usuario relevante. Un agente que responde preguntas de FAQ sobre un producto estático puede funcionar perfectamente con solo memoria a corto plazo (el contexto de la conversación actual) y una base de conocimiento bien construida mediante RAG.
No necesitas memoria episódica si: tu agente no aprende de interacciones pasadas de forma estructurada. Si las conversaciones son cortas, el tipo de problema es siempre el mismo y las respuestas no dependen de "cómo salió la última vez", puedes prescindir de ella.
No necesitas memoria procedimental avanzada (metaprompting) si: el comportamiento del agente es estable y bien definido desde el inicio. El metaprompting añade complejidad y puede generar comportamientos inesperados si no se supervisa bien.
La regla práctica: empieza con memoria a corto plazo + RAG para la semántica, mide dónde falla, y añade complejidad solo cuando los datos lo justifican.
La memoria en la atención al cliente: de la demo al caso real
Todo esto es muy interesante en abstracto. Vamos a aterrizar con un caso concreto.
Una empresa de SaaS con 300 clientes usa un agente de IA para atención al cliente. Sin memoria persistente, el agente gestiona bien las preguntas puntuales pero empieza a fallar en las situaciones más comunes de negocio real:
- Un cliente llama por tercera vez sobre el mismo problema porque el agente no recuerda las dos conversaciones anteriores
- El agente ofrece el plan premium a un cliente que ya lo tiene
- Un cliente menciona en el turno 6 que trabaja con React, y en el turno 7 el agente le recomienda una integración incompatible con React porque no ha "retenido" ese dato
Con una arquitectura de memoria bien diseñada, el mismo agente puede:
Al inicio de cada conversación: recuperar de la memoria a largo plazo el perfil del cliente (sector, tamaño, plan, tecnologías, historial de incidencias), los recuerdos episódicos más relevantes (últimas interacciones, problemas abiertos) y las preferencias semánticas acumuladas (canal preferido, horario habitual, nivel técnico). Todo esto se inyecta en el contexto como briefing inicial antes de procesar el primer mensaje del usuario.
Durante la conversación: el agente mantiene el hilo gracias a la memoria a corto plazo. Si el usuario cambia de tema y vuelve al anterior, el agente lo sigue. Si menciona algo que merece guardarse (un nuevo dato de empresa, una preferencia), el sistema lo extrae y lo encola para escritura en background.
Al cierre de la conversación: se genera un resumen estructurado de la sesión, se actualizan los recuerdos episódicos con el resultado (problema resuelto, escalado, pendiente) y se actualiza el perfil semántico del usuario si hay datos nuevos.
El resultado no es solo una mejor experiencia de cliente. Es un agente que aprende de cada conversación sin necesidad de reentrenamiento, que conoce a cada cliente mejor con el tiempo, y que puede anticiparse a problemas antes de que escalen.
Para profundizar en cómo se gestiona el estado y la persistencia de un agente paso a paso, puedes leer nuestra guía sobre state y checkpointing en LangGraph, donde explicamos el enfoque técnico con ejemplos reales.
Gestión del contexto en sistemas multiagente
Hasta aquí hemos hablado de un solo agente con memoria. Pero en los sistemas multiagente, el problema de la memoria se vuelve más complejo.
Cuando varios agentes colaboran para resolver una tarea —un agente de investigación, un agente redactor, un agente revisor—, cada uno tiene su propio contexto pero necesitan compartir cierta información. Hay tres patrones habituales de gestión de memoria compartida:
Blackboard pattern: todos los agentes leen y escriben en un estado compartido centralizado. Sencillo de implementar, puede crear cuellos de botella en sistemas grandes.
Mensajería explícita: los agentes se pasan información entre sí de forma explícita, como parámetros de función. Más controlado, pero requiere que el orquestador sepa qué información necesita cada agente en cada paso.
Memoria compartida con namespace: cada agente tiene su propia "zona" de memoria, pero puede leer zonas de otros agentes cuando tiene permiso. Más flexible y escalable, pero más complejo de diseñar.
En LangGraph, el state del grafo actúa de forma natural como memoria compartida entre nodos: cada nodo puede leer el state completo y modificar las claves que tiene asignadas. Es el patrón más limpio para sistemas multiagente construidos con este framework.
Preguntas frecuentes sobre memoria en agentes de IA
¿Cuál es la diferencia entre memoria a corto y largo plazo en la práctica? La memoria a corto plazo vive en el context window: es el historial de mensajes de la sesión actual. Desaparece cuando acaba la conversación. La memoria a largo plazo se almacena externamente (vector store, base de datos) y persiste entre sesiones. El agente la consulta activamente cuando la necesita.
¿Necesito implementar todos los tipos de memoria? No. Empieza con memoria a corto plazo (historial de conversación) y memoria semántica básica (RAG sobre tu base de conocimiento). Añade memoria episódica y procedimental cuando tengas casos de uso específicos que lo justifiquen y datos que demuestren que el sistema falla sin ellas.
¿Qué es mem0 y cuándo usarlo? Mem0 es una librería/servicio que automatiza la gestión de memoria persistente para agentes: extrae recuerdos de conversaciones, los consolida y los recupera cuando son relevantes. Es especialmente útil si no quieres construir tu propio sistema de extracción y actualización de recuerdos desde cero.
¿Qué es el context engineering? Es la disciplina de decidir qué información incluir en el prompt de cada llamada al LLM. No es lo mismo que prompt engineering (redacción de instrucciones): es arquitectura de información, diseñar dinámicamente qué memorias recuperar y cómo presentarlas al modelo para maximizar la calidad de la respuesta.
¿El LangGraph checkpointing sirve para memoria a largo plazo? Sí y no. El checkpointing de LangGraph persiste el state del agente entre sesiones, lo que permite reanudar conversaciones. Pero el state de LangGraph está pensado para el flujo de la tarea en curso, no para memoria semántica de largo plazo de múltiples usuarios. Para eso necesitas un vector store externo. Los dos se complementan: LangGraph para el estado operativo, vector store para la memoria acumulada del usuario.
¿Cómo afecta la memoria al coste de la API? Más contexto = más tokens = más coste. El context engineering bien hecho reduce costes al inyectar solo los recuerdos relevantes, no todo el historial. Un sistema de memoria eficiente cuesta más en infraestructura de almacenamiento (vector store, base de datos) pero puede reducir costes de LLM al producir respuestas correctas en menos turnos.
¿Es seguro almacenar conversaciones de clientes en un vector store? Depende de cómo lo implementes. Los sistemas de producción serios cifran los datos en reposo y en tránsito, separan la memoria por usuario con namespaces o filtros de metadatos estrictos, y implementan políticas de retención y eliminación de datos. Cumplir con el RGPD en España significa también dar a los usuarios el derecho a eliminar sus datos almacenados, lo que requiere que el sistema de memoria soporte borrado granular por usuario.
De un agente que olvida a uno que aprende
La memoria no es un feature secundario en los agentes de IA. Es la diferencia entre un sistema que responde y uno que evoluciona.
Un agente sin memoria necesita que el usuario repita su contexto en cada sesión, trata a cada conversación como un evento aislado y es incapaz de personalizar más allá de lo que entra en el prompt actual. Un agente con una arquitectura de memoria bien diseñada aprende de cada interacción, construye un modelo del usuario que mejora con el tiempo y puede anticiparse a necesidades antes de que el cliente las exprese.
La implementación tiene capas: memoria a corto plazo para el hilo de la conversación, memoria a largo plazo con vector stores para la persistencia, LangGraph para el state y el checkpointing, mem0 para automatizar la extracción de recuerdos, y context engineering para decidir qué inyectar en cada llamada. No necesitas todo desde el día uno. Pero sí necesitas saber qué vas a necesitar antes de diseñar tu arquitectura.
En GuruSup construimos esta arquitectura para empresas que quieren que su agente de IA no solo responda bien hoy, sino que sea mejor mañana. Si estás en ese punto del camino, cuéntanos tu caso y te mostramos cómo lo resolvemos en producción.