Orquestacion Multi-Agente: Como Coordinar Agentes IA a Escala
Un solo agente IA puede responder preguntas. Mil agentes IA trabajando juntos pueden gestionar un negocio entero.

Un solo agente IA puede responder preguntas. Mil agentes IA trabajando juntos pueden gestionar un negocio entero. La diferencia es la orquestacion multi-agente , la disciplina de ingenieria que coordina agentes especializados para que dividan el trabajo, compartan contexto, gestionen fallos y produzcan resultados coherentes. Sin orquestacion, los agentes duplican esfuerzos, se contradicen entre si y pierden contexto en cada handoff. Con ella, se obtienen sistemas que resuelven tickets de clientes, procesan reclamaciones de seguros y gestionan cadenas de suministro con minima intervencion humana.
Esta guia cubre los conceptos fundamentales, patrones y detalles de implementacion de la orquestacion multi-agente. Si quieres conocer el mercado arquitectonico mas amplio , incluyendo Mixture of Experts y las ventajas y desventajas de los agentes individuales , consulta la guia completa de arquitecturas de agentes IA. Para detalles a nivel de protocolo sobre como los agentes intercambian mensajes, consulta protocolos de comunicacion entre agentes: MCP y A2A.
Que es la orquestacion multi-agente
La orquestacion multi-agente es la capa de coordinacion que gobierna como multiples agentes IA colaboran para completar tareas que exceden la capacidad de cualquier agente individual. Define tres cosas: enrutamiento de tareas (que agente se encarga de cada subtarea), flujo de contexto (como se transmite la informacion entre agentes) y gestion del ciclo de vida (como los agentes arrancan, fallan, reintentan y terminan). Segun la investigacion de IBM sobre orquestacion de agentes, la orquestacion es lo que transforma una coleccion de agentes independientes en un sistema coherente capaz de ejecutar flujos de trabajo complejos y de multiples pasos.
El concepto toma prestado mucho de la ingenieria de sistemas distribuidos. Asi como los microservicios necesitan un service mesh, balanceadores de carga y circuit breakers, los agentes IA necesitan infraestructura analoga para descubrimiento, enrutamiento y tolerancia a fallos. La diferencia critica es el no-determinismo. Una API REST devuelve respuestas predecibles ante entradas identicas. Un agente potenciado por un LLM puede tomar caminos de razonamiento diferentes con el mismo prompt. Esto hace que la orquestacion de agentes sea mas dificil que la orquestacion tradicional de servicios , no puedes confiar en un comportamiento deterministico, asi que tu capa de coordinacion debe contemplar la variabilidad tanto en latencia como en calidad de las respuestas.
A nivel de implementacion, la orquestacion tipicamente involucra cuatro componentes: un registro de agentes disponibles y sus capacidades, un router que mapea las tareas entrantes al mejor agente o secuencia de agentes, un almacen de estado para el contexto compartido y el historial de conversaciones, y un supervisor que monitoriza timeouts, reintentos y escalaciones.
Por que los agentes individuales tienen un techo
Un agente monolitico que intenta manejar cada dominio se enfrenta a tres limites concretos. Primero, saturacion de la ventana de contexto. Incluso con modelos de 200K tokens como Claude Opus 4.6 o GPT-5.4 Turbo, meter todo el conocimiento, herramientas e historial de conversacion en un solo contexto degrada el rendimiento. La investigacion de Anthropic demuestra que la precision cae de forma medible una vez que la utilizacion del contexto supera el 60-70% de la ventana, particularmente en tareas de recuperacion de informacion posicionadas en la mitad del contexto. Cuando solo el prompt del sistema consume 30K tokens y una conversacion anade otros 50K, has perdido una porcion significativa de la capacidad efectiva de razonamiento del modelo.
Segundo, proliferacion de herramientas. Un unico agente de soporte al cliente podria necesitar acceso a un CRM, un sistema de facturacion, una base de conocimiento, un rastreador de envios y un procesador de devoluciones. Cada herramienta anade tokens al prompt del sistema y complejidad de decision a la logica de enrutamiento. Una vez que un agente tiene acceso a 15-20 herramientas, la precision en la seleccion de herramientas cae por debajo del 80%. El agente empieza a llamar a la herramienta equivocada, pasar parametros alucinados o saltarse herramientas por completo. La solucion no son modelos mas grandes con contextos mas largos, sino agentes mas pequenos y especializados , cada uno con 3-5 herramientas que conocen a fondo.
Tercero, acumulacion de latencia. Un agente monolitico maneja las tareas de forma secuencial: clasificar la intencion, recuperar conocimiento, consultar la base de datos, formular una respuesta, validar la salida. Cada paso anade 1-3 segundos de tiempo de inferencia del LLM. Una cadena de cinco pasos toma 5-15 segundos de principio a fin. La orquestacion multi-agente habilita el paralelismo: mientras un agente de recuperacion busca articulos en la base de conocimiento, un agente de CRM obtiene el historial del cliente simultaneamente. La latencia total se aproxima al paso individual mas largo, no a la suma de todos los pasos.
Coordinacion centralizada vs descentralizada
Todo sistema multi-agente se situa en un espectro entre dos extremos de coordinacion. La coordinacion centralizada utiliza un unico orquestador que recibe todas las tareas, decide que agentes invocar y agrega los resultados. Piensa en ello como un gerente de call center que asigna tickets a especialistas. El orquestador tiene visibilidad completa del estado del sistema, controla el orden de ejecucion y posee el registro de auditoria. Frameworks como LangGraph y CrewAI utilizan este modelo por defecto porque ofrece el mejor equilibrio entre simplicidad, facilidad de depuracion y observabilidad.
El compromiso es directo: la coordinacion centralizada es mas simple de construir y razonar, pero el orquestador es un punto unico de fallo y un cuello de botella de rendimiento. A 100 solicitudes concurrentes por segundo, un unico orquestador ejecutando inferencia de GPT-5.4 se convierte en el limitador de tasa de todo el sistema. Puedes mitigar esto con escalado horizontal (multiples instancias del orquestador detras de un balanceador de carga) o descargando la clasificacion a un modelo mas barato y rapido como GPT-5.4-mini o Claude Haiku 4.5.
La coordinacion descentralizada elimina el controlador central por completo. Los agentes se comunican entre pares, pasando tareas mediante handoffs o colas de mensajes compartidas. El framework Swarm de OpenAI demuestra esto con transferencias ligeras entre agentes, donde cada agente decide localmente si manejar una tarea o pasarla a un par. El comportamiento del sistema emerge de reglas locales en lugar de planificacion central , similar a como las colonias de hormigas resuelven problemas de optimizacion sin que ninguna hormiga individual comprenda el objetivo global.
Los sistemas descentralizados son mas resilientes (sin punto unico de fallo) y escalan horizontalmente al anadir agentes, pero son significativamente mas dificiles de depurar, observar y predecir. Los bucles de handoff, donde el Agente A pasa al Agente B que vuelve a pasar al Agente A, son un modo de fallo comun que requiere condiciones de guarda cuidadosas. La guia de patrones de diseno de agentes IA de Microsoft recomienda empezar centralizado y descentralizar solo cuando se encuentren cuellos de botella concretos de escalabilidad. La mayoria de los equipos en produccion nunca necesitan descentralizacion completa. Una comparacion detallada de los cinco patrones estructurales , orquestador-trabajador, swarm, mesh, jerarquico y pipeline , esta disponible en nuestra guia de patrones de orquestacion de agentes.
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
El patron orquestador-trabajador
El patron de orquestacion multi-agente mas desplegado en produccion es el orquestador-trabajador. Un orquestador central recibe las tareas entrantes, clasifica la intencion, descompone solicitudes complejas en subtareas, enruta cada subtarea a un agente trabajador especializado y combina los resultados en una respuesta final. Los trabajadores son sin estado, especificos de dominio y no tienen conocimiento unos de otros. Este patron representa aproximadamente el 70% de los despliegues multi-agente en produccion, segun estudios de caso publicos de empresas que ejecutan soporte al cliente, procesamiento de documentos y automatizacion operacional basados en agentes.
La implementacion requiere cuatro componentes diferenciados:
- Clasificador de intencion , determina el dominio (facturacion, envios, soporte tecnico) y el nivel de complejidad (consulta simple vs. resolucion de multiples pasos). Los clasificadores rapidos utilizan similitud de embeddings con latencia de 50-100ms. Los clasificadores basados en LLM son mas precisos pero anaden 1-2 segundos. Los enfoques hibridos ejecutan primero una coincidencia rapida por embeddings y recurren al LLM solo cuando la confianza esta por debajo de un umbral, tipicamente 0.85.
- Descomponedor de tareas , divide solicitudes compuestas en subtareas atomicas. El mensaje del cliente "cancela mi pedido y emite un reembolso" se convierte en dos subtareas: cancelacion_pedido y procesamiento_reembolso. La descomposicion puede ser basada en reglas (patrones regex, coincidencia de palabras clave) o basada en LLM (mas flexible pero con mayor latencia). El descomponedor tambien asigna prioridad: en el ejemplo, la cancelacion debe completarse antes de que el reembolso pueda ejecutarse.
- Router , mapea cada subtarea al mejor agente trabajador disponible segun la coincidencia de capacidades, la carga actual y la precision historica. Los routers avanzados usan algoritmos multi-armed bandit para equilibrar exploracion (probar agentes infrautilizados) y explotacion (usar el agente con mejor rendimiento). Los routers mas simples usan mapas de capacidades estaticos donde cada agente registra sus intenciones soportadas al arrancar.
- Agregador , combina las salidas de los trabajadores en una respuesta final coherente. Esto puede ser una concatenacion simple para subtareas independientes, sintesis basada en LLM para tareas que requieren coherencia narrativa, o fusion estructurada cuando las salidas de los trabajadores siguen un esquema definido.
class Orchestrator:
def handle(self, task, context):
intent = self.classifier.classify(task)
subtasks = self.decomposer.decompose(task, intent)
# Ejecucion paralela para subtareas independientes
futures = []
for subtask in subtasks:
worker = self.router.select(subtask, intent)
futures.append(worker.execute_async(subtask, context))
results = await asyncio.gather(*futures)
return self.aggregator.merge(results, context)El patron orquestador-trabajador es dominante porque ofrece un flujo de control predecible, observabilidad centralizada y una separacion limpia de responsabilidades. Anadir un nuevo dominio significa registrar un nuevo agente trabajador sin modificar el orquestador. Eliminar un trabajador que falla significa que el router lo omite y delega a un respaldo.
Gestion de estado y paso de contexto
El problema mas dificil en la orquestacion multi-agente no es el enrutamiento , es el estado. Cuando un cliente dice "necesito ayuda con mi pedido reciente" a un agente de triaje, y el agente de triaje enruta a un especialista en facturacion, que contexto se transfiere? El historial completo de la conversacion? Solo el ultimo mensaje? Un resumen estructurado? Demasiado poco contexto y el agente trabajador pide al cliente que repita todo. Demasiado contexto y desperdicias tokens, aumentas la latencia y corres el riesgo de que el agente trabajador se distraiga con informacion irrelevante.
Los sistemas en produccion tipicamente implementan una de tres estrategias de gestion de estado:
- Reenvio de contexto completo , cada agente recibe el historial completo de la conversacion. Simple de implementar pero costoso. Un hilo de 50 mensajes con 4 handoffs de agentes significa que el 5to agente procesa aproximadamente 200 mensajes. Los costes de tokens escalan cuadraticamente con los handoffs, y la utilizacion de la ventana de contexto se convierte en un cuello de botella mas rapido de lo esperado.
- Objetos de contexto estructurado , el orquestador mantiene un objeto de contexto tipado (customer_id, detected_intent, extracted_entities, resolution_status, active_subscriptions) y pasa solo los campos relevantes a cada trabajador. Este es el enfoque mas eficiente en tokens y el que la mayoria de los frameworks recomiendan. LangGraph usa canales de estado tipados para esto; CrewAI usa objetos de memoria compartida. Los objetos de contexto tipicos son de 200-500 tokens frente a 5.000-20.000 tokens del reenvio completo de conversacion.
- Contexto resumido , un LLM genera un resumen comprimido de la conversacion en cada punto de handoff. Esto reduce el conteo de tokens en un 70-90% comparado con el reenvio completo, pero introduce perdida de informacion y anade 500ms-1.5s de latencia de resumen por handoff. Ideal para conversaciones de larga duracion donde el historial completo excede la ventana de contexto, o cuando necesitas preservar matices conversacionales que los objetos estructurados no pueden capturar.
Para estado persistente entre sesiones, la mayoria de los despliegues en produccion utilizan Redis o PostgreSQL como almacen de respaldo, indexado por conversation_id. Esto permite a los agentes retomar el contexto despues de desconexiones, soporta registro de auditoria para cumplimiento normativo y permite a los supervisores inspeccionar la cadena de resolucion completa despues de los hechos. Como los protocolos MCP y A2A manejan el contexto a nivel de cable se cubre en nuestra guia sobre protocolos de comunicacion entre agentes.
Manejo de errores y respaldos
Los agentes fallan. Los proveedores de LLM tienen caidas. Los limites de tasa se alcanzan inesperadamente. Los agentes alucinan. Las llamadas a herramientas devuelven errores. En un sistema de agente unico, el fallo es simple: el agente falla y el usuario reintenta. En un sistema multi-agente, un fallo en un agente puede propagarse en cascada por toda la cadena de orquestacion. El manejo de errores debe ser una preocupacion de diseno explicita y de primera clase , nunca una ocurrencia tardia.
El manual estandar de produccion incluye cuatro mecanismos:
- Timeouts , cada invocacion de agente tiene un plazo limite, tipicamente 30-60 segundos para llamadas al LLM. Si el trabajador no responde dentro del timeout, el orquestador lo marca como fallido e invoca la estrategia de respaldo. Sin timeouts, un solo agente bloqueado paraliza la solicitud completa indefinidamente.
- Reintentos con backoff exponencial , los fallos transitorios como limites de tasa y timeouts de red disparan reintentos automaticos. Configuracion estandar: 3 reintentos con retrasos de 1s, 2s, 4s mas jitter. Restriccion critica: los reintentos deben ser idempotentes. Si un agente de facturacion cobro exitosamente al cliente pero la respuesta se perdio en transito, reintentar no debe generar un doble cobro. Esto significa que los agentes trabajadores necesitan claves de idempotencia o guardas transaccionales.
- Agentes de respaldo , si el trabajador principal falla despues de todos los reintentos, el router delega a un respaldo. La jerarquia de respaldo tipicamente sigue: agente especialista alternativo, luego un agente basado en reglas mas simple, luego un modelo LLM mas barato (por ejemplo, cayendo de GPT-5.4 a GPT-5.4 Turbo), y finalmente una cola de escalacion humana. Cada nivel intercambia capacidad por fiabilidad.
- Circuit breakers , si un agente trabajador falla mas de N veces en M minutos (un umbral comun es 5 fallos en 2 minutos), el circuit breaker se abre y todo el trafico se redirige automaticamente lejos de ese agente. El circuito se abre parcialmente despues de un periodo de enfriamiento y prueba con una sola solicitud antes de restaurar el trafico completamente. Esto evita que un agente degradado consuma recursos y produzca resultados erroneos a escala.
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
El modo de fallo mas ignorado es el fallo semantico , cuando un agente devuelve una respuesta que es tecnicamente valida (formato correcto, sin errores) pero factualmente incorrecta o contextualmente inapropiada. Un agente de facturacion que reporta con confianza "no se encontraron cargos" cuando el sistema de pagos devolvio una respuesta ambigua es un fallo semantico. Detectar esto requiere validacion de salida: verificar que la respuesta coincida con el esquema esperado, contenga los campos requeridos, no contradiga hechos establecidos en el contexto y cumpla un umbral minimo de confianza. Algunos equipos de produccion ejecutan un agente ligero de "juez" que puntua las salidas de los trabajadores antes de que lleguen al usuario, anadiendo 500-800ms de latencia pero capturando el 15-20% de errores que de otro modo alcanzarian a los clientes.
Ejemplo real: soporte al cliente
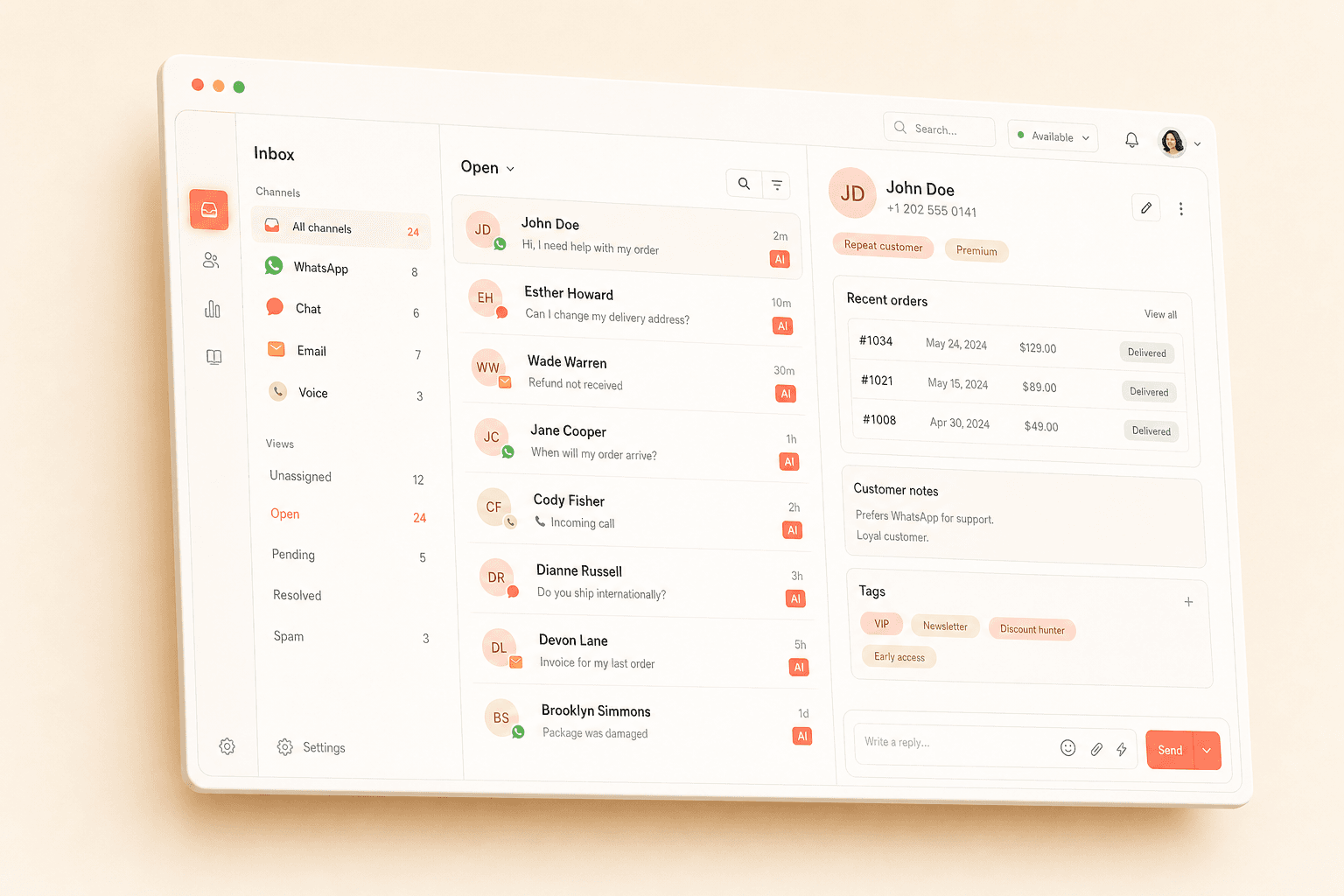
El soporte al cliente es el caso de uso canonico para la orquestacion multi-agente porque combina clasificacion de intenciones, enrutamiento por dominio, uso de herramientas y continuidad de contexto en un unico flujo de trabajo. Agentforce de Salesforce, Fin de Intercom y los agentes IA de Zendesk utilizan variaciones del patron orquestador-trabajador por esta razon. Veamos un ejemplo concreto para ver como interactuan los componentes.
Un cliente envia: "Me han cobrado dos veces por mi suscripcion y quiero actualizar al plan enterprise". El Agente de Triaje recibe este mensaje y lo clasifica como una solicitud compuesta con dos intenciones: disputa_facturacion (alta prioridad, porque los cargos no resueltos danan la confianza) y actualizacion_plan (prioridad media). Crea un objeto de contexto estructurado con el customer_id, las intenciones detectadas, las entidades extraidas (suscripcion, plan enterprise) y una cola de prioridad.
El orquestador despacha ambas subtareas en paralelo. Un Agente de Facturacion recibe la subtarea de disputa_facturacion junto con el customer_id y la entidad de suscripcion del objeto de contexto. Este especialista tiene acceso a tres herramientas: una API de pasarela de pagos, una base de datos de suscripciones y un procesador de reembolsos. Consulta el historial de pagos, confirma el cargo duplicado (dos transacciones identicas con 3 segundos de diferencia , un artefacto clasico de reintento de pasarela), inicia un reembolso y devuelve un resultado estructurado: {status: "reembolsado", amount: "$49.00", transaction_id: "txn_abc123", eta: "3-5 dias habiles"}.
Simultaneamente, un Agente de Ventas recibe la subtarea de actualizacion_plan. Accede al catalogo de productos, verifica el plan actual del cliente y su ciclo de facturacion, calcula el coste prorrateado de la actualizacion y devuelve: {current_plan: "pro", proposed_plan: "enterprise", prorated_cost: "$125.00", features_added: ["SSO", "registros de auditoria", "SLAs personalizados", "garantia de uptime del 99.95%"]}.
El agregador combina ambas salidas de los trabajadores en una unica respuesta coherente: "Encontramos el cargo duplicado y hemos emitido un reembolso de $49.00 a su tarjeta terminada en 4242 , esperelo en 3-5 dias habiles. Respecto a la actualizacion enterprise, el coste prorrateado para el resto de su ciclo de facturacion es de $125.00, lo cual anade SSO, registros de auditoria, SLAs personalizados y una garantia de uptime del 99.95%. Desea proceder?" Tiempo total de ejecucion: 3.2 segundos, porque ambos agentes se ejecutaron en paralelo.
Esta es la arquitectura que GuruSup implementa en produccion. El orquestador de triaje coordina mas de 800 agentes especializados en los dominios de Soporte, Ventas y Operaciones, logrando un 95% de resolucion autonoma. La capa de triaje clasifica intenciones y enruta basandose en extraccion de entidades, nivel del cliente e historial de conversacion. Las transferencias de contexto usan objetos estructurados , no historial completo de conversacion — reduciendo la latencia de handoff a menos de 200ms mientras mantienen la continuidad completa de la conversacion. El Agente de Facturacion nunca ve datos del catalogo de productos. El Agente de Ventas nunca ve registros de pago. Este aislamiento de alcance previene alucinaciones entre dominios y reduce el consumo de tokens por solicitud de cada agente en un 60-70% comparado con un enfoque monolitico.
Para los detalles de ingenieria sobre el despliegue y monitorizacion de sistemas como este en produccion, consulta nuestra guia sobre construccion de sistemas multi-agente en produccion.
FAQ
¿Que es la orquestacion multi-agente?
La orquestacion multi-agente es la capa de coordinacion que gobierna como multiples agentes IA especializados colaboran para completar tareas complejas. Se encarga del enrutamiento de tareas (decidir que agente procesa que subtarea), el paso de contexto (compartir informacion relevante entre agentes sin saturar sus ventanas de contexto) y la gestion del ciclo de vida (arrancar, monitorizar, reintentar y terminar agentes). Sin orquestacion, los agentes operan de forma aislada y no pueden producir resultados coherentes de multiples pasos.
¿Cual es la diferencia entre orquestacion de agentes centralizada y descentralizada?
La orquestacion centralizada usa un unico controlador (el orquestador) que recibe todas las tareas, las asigna a agentes trabajadores y agrega los resultados. Ofrece simplicidad y visibilidad completa pero crea un punto unico de fallo. La orquestacion descentralizada elimina el controlador central — los agentes se comunican entre pares y toman decisiones de enrutamiento locales basadas en reglas de handoff. Es mas resiliente y escalable pero significativamente mas dificil de depurar y observar. La mayoria de los sistemas en produccion comienzan centralizados y solo descentralizan cuando encuentran cuellos de botella concretos de rendimiento.
¿Que frameworks soportan orquestacion multi-agente?
Los frameworks lideres incluyen LangGraph (flujos de trabajo basados en grafos con canales de estado tipados), CrewAI (equipos de agentes basados en roles con delegacion y memoria integrada), Microsoft AutoGen (patrones conversacionales multi-agente con soporte para intervencion humana) y OpenAI Swarm (handoffs ligeros entre pares para coordinacion descentralizada). Cada framework favorece patrones diferentes: LangGraph destaca en orquestador-trabajador, CrewAI en equipos jerarquicos, AutoGen en conversacion colaborativa y Swarm en handoffs descentralizados. La eleccion depende de tu patron de coordinacion, no del marketing del framework.
Mira la Orquestacion Multi-Agente en Accion
GuruSup ejecuta mas de 800 agentes IA en produccion con un 95% de resolucion autonoma.
Reserva una Demo Gratis