Por qué tu agente de IA falla 1 de cada 3 veces (aunque la demo funcione)
Descubre por qué los agentes de IA que funcionan en demo fallan en producción real. Explicamos Pass^k, tau-bench y cómo evaluar la fiabilidad de un agente de IA de verdad.
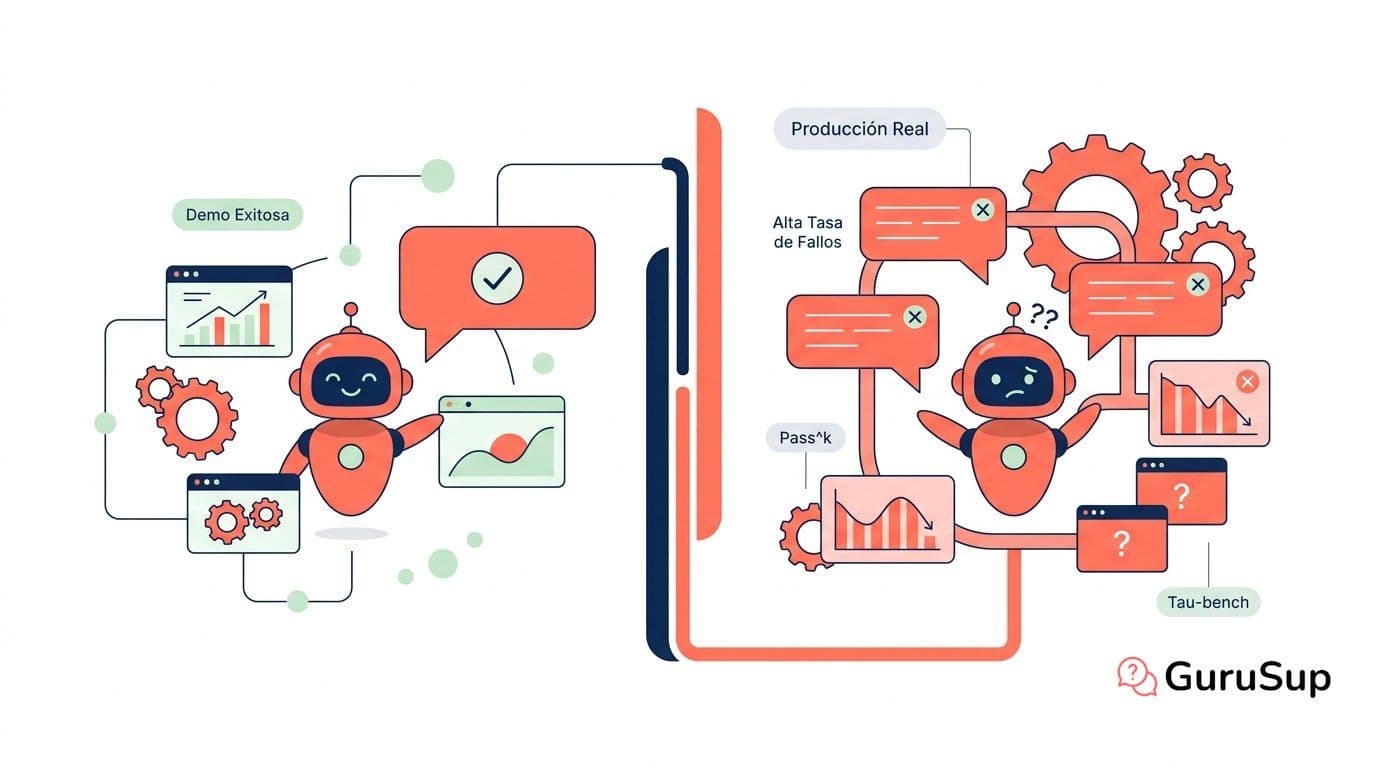
Tabla de contenidos
- ¿Por qué un agente que funciona en la demo falla en producción?
- ¿Qué es tau-bench y por qué importa para evaluar la fiabilidad de un agente?
- ¿De dónde viene la inconsistencia? Las cuatro fuentes de fallo real
- ¿Cómo se evalúa de verdad la fiabilidad de un agente de IA?
- ¿Qué preguntar a tu proveedor antes de contratar?
- ¿Cómo impacta la fiabilidad en las métricas de negocio?
- ¿Qué diferencia a un agente fiable de uno que simplemente hace buenas demos?
- Fiabilidad en sistemas multiagente: el problema se multiplica
- El problema específico de los agentes en atención al cliente
- ¿Cuánta fiabilidad es suficiente?
- ¿Qué hacer si ya tienes un agente desplegado que falla?
- Preguntas frecuentes sobre fiabilidad y evaluación de agentes de IA
La demo del agente iba perfecta. Lo viste tú. Lo vio tu equipo. El proveedor hizo la demo en vivo, la conversación fue fluida, el agente gestionó la incidencia en segundos, consultó la API, aplicó la política correcta, cerró el ticket. Firmaste. Desplegaste. Y tres semanas después tienes un CSAT que no mejora, escalaciones que siguen subiendo y un agente que resuelve bien cuando quiere, pero que en producción no es el mismo que en aquella sala de reuniones.
El problema no es que el proveedor te engañara. El problema es que la demo mide algo distinto de lo que mide la producción. Y si nadie te explicó esa diferencia antes de firmar, este artículo es para ti.
En GuruSup llevamos tiempo montando agentes de IA para atención al cliente en empresas reales, y lo que hemos aprendido es que la fiabilidad de un agente de IA no se mide por si funciona en un intento controlado. Se mide por si funciona de forma consistente, sobre el mismo tipo de tarea, una y otra vez, con usuarios reales que no siguen el guion.
¿Por qué un agente que funciona en la demo falla en producción?
Porque la demo es Pass^1. La producción es Pass^k.
Déjame explicarlo bien.
Pass^1 es la tasa de éxito en un único intento sobre una tarea concreta. Es lo que ves en una demo, en una prueba de concepto o en el vídeo del proveedor. El agente hace la tarea una vez, le sale bien, y eso se interpreta como "el agente funciona". La métrica es real. El problema es que no te dice nada sobre lo que pasa la segunda vez, ni la décima, ni cuando el caso llega a las 11 de la noche con un cliente que escribe con faltas.
Pass^k mide algo distinto: la probabilidad de que el agente complete con éxito esa misma tarea en k intentos independientes. No es un promedio; es una métrica de consistencia. Y aquí está el hallazgo que cambia cómo hay que pensar en los agentes de IA: un agente con un Pass^1 aparentemente alto —digamos que resuelve correctamente ocho de cada diez tareas en evaluación— puede tener un Pass^k mucho más bajo cuando se mide la consistencia en múltiples intentos sobre el mismo tipo de caso. El decaimiento existe porque los agentes de IA introducen aleatoriedad en cada paso: en cómo interpretan el contexto, en qué herramienta llaman, en cómo leen la respuesta de esa herramienta, en cómo aplican la política interna.
Esa aleatoriedad es manejable. Pero si no la mides, no la ves hasta que ya tienes un problema en producción.
¿Por qué el Pass^k decae aunque el modelo no cambie?
Aquí está la parte que más sorprende a los equipos técnicos que se acercan a este tema por primera vez: el decaimiento de Pass^k no requiere que el modelo empeore. Un modelo que no ha cambiado en absoluto puede tener un Pass^k significativamente más bajo que su Pass^1 simplemente porque el proceso de generación del LLM es estocástico por diseño.
Los grandes modelos de lenguaje no generan la misma respuesta siempre que reciben el mismo input. La temperatura de generación introduce variabilidad deliberada para que las respuestas no sean mecánicas. En tareas de respuesta única —"¿Cuál es la capital de Francia?"— esa variabilidad es irrelevante porque el espacio de respuestas correctas es amplio. En tareas de agente —llamar a la herramienta correcta, con los parámetros correctos, en el momento correcto del agent loop, aplicando la política adecuada— esa variabilidad se convierte en inconsistencia. Cada decisión dentro del loop tiene un margen de error que se multiplica con el número de decisiones que el agente tiene que tomar para completar la tarea.
Hay otra fuente de variabilidad que casi nadie menciona: el contexto de la conversación. Dos usuarios que hacen exactamente la misma solicitud con palabras ligeramente diferentes pueden llegar a resultados diferentes si el agente interpreta el contexto de forma distinta. Y eso ocurre incluso con temperatura cero, porque la interpretación del contexto depende también del estado del historial de la conversación, de qué herramientas están disponibles en ese momento, y de cómo la política de dominio está formulada en el prompt del sistema.
Entender estas fuentes de variabilidad es el primer paso para reducirlas. Y reducirlas sistemáticamente es lo que convierte un Pass^1 aceptable en un Pass^k robusto.
¿Qué es tau-bench y por qué importa para evaluar la fiabilidad de un agente?
Cuando empezamos a buscar un marco riguroso para evaluar agentes de IA en escenarios de atención al cliente, nos topamos con tau-bench, el benchmark desarrollado por Sierra Research (arXiv:2406.12045). Es uno de los pocos marcos de evaluación diseñados específicamente para medir agentes que usan herramientas reales —API calls, consulta de bases de datos, aplicación de políticas de negocio— en conversaciones simuladas con un usuario.
Lo que hace tau-bench diferente de otros benchmarks es que no evalúa el agente sobre preguntas de respuesta única. Evalúa el ciclo completo: el agente recibe un caso, tiene acceso a herramientas (APIs que puede llamar), tiene que interpretar una política de dominio (las reglas de negocio), y tiene que sostener una conversación con un usuario simulado hasta resolver el caso. El benchmark mide si el agente completó la tarea correctamente al final del proceso, no solo si dio la respuesta "correcta" a una pregunta aislada.
Y lo mide con Pass^k.
Eso convierte tau-bench en algo especialmente relevante para empresas que están evaluando o ya tienen desplegado un agente de IA para atención al cliente: replica exactamente el escenario real. Política de empresa que el agente debe conocer y aplicar. Herramientas que puede fallar en llamar correctamente. Usuario que no siempre explica bien lo que quiere. Conversaciones que se alargan o dan giros inesperados.
Si tu proveedor nunca ha mencionado tau-bench ni Pass^k, tienes una pregunta que hacerle.
Dicho esto, tau-bench no es una herramienta que cualquier empresa vaya a correr internamente. Es un marco de referencia y una forma de pensar que debería informar cómo se diseña y se evalúa cualquier agente de producción, independientemente de las herramientas concretas que se usen. Lo relevante no es el nombre del benchmark; es el concepto que representa: mide la consistencia, no solo el éxito puntual. Un proveedor que evalúa sus agentes con ese criterio te va a dar algo muy diferente de uno que solo te muestra el Pass^1 de sus demos. Y en producción, con clientes reales, esa diferencia se nota desde la primera semana.
¿De dónde viene la inconsistencia? Las cuatro fuentes de fallo real
Saber que un agente falla 1 de cada 3 veces no sirve de mucho si no sabes por qué. La inconsistencia de un agente en producción suele venir de cuatro fuentes distintas, y casi siempre se combinan.
¿Falla la herramienta o falla el agente al usarla?
Un agente de IA en atención al cliente no trabaja solo. Llama a herramientas: consulta el estado de un pedido, aplica un descuento, abre un ticket, consulta el histórico del cliente. Cada tool call es un punto de fallo potencial.
El fallo puede ser de la herramienta en sí (la API devuelve un error, tarda demasiado, devuelve un formato inesperado). Pero más frecuente, y más difícil de ver, es el fallo del agente al interpretar qué herramienta llamar, con qué parámetros, en qué momento del agent loop. Un agente que en la demo llama siempre a la herramienta correcta puede, en producción, elegir mal cuando el usuario introduce el caso con palabras diferentes o cuando hay dos herramientas parecidas disponibles.
La inconsistencia en tool use es una de las primeras cosas que hay que medir, y casi siempre la primera que se ignora en las demos.
¿Aplica bien las políticas de negocio?
Cada empresa tiene reglas. Cuándo se puede hacer una devolución sin justificación. Cuándo hay que escalar. Qué información se puede compartir con el cliente y cuál no. Qué tono usar en situaciones de conflicto. Esas políticas se le dan al agente en forma de instrucciones, y el agente las interpreta.
El problema es que la interpretación no es determinista. Un agente puede aplicar correctamente la política de devoluciones el 85% de las veces y equivocarse el 15% restante de formas que no son aleatorias: se equivoca más cuando el usuario planta un caso que mezcla dos políticas a la vez, o cuando la solicitud contradice parcialmente la política pero tiene una excepción legítima. Esos son los casos límite, y los casos límite son exactamente los que no aparecen en la demo.
La evaluación con tau-bench incluye políticas de dominio precisamente por esto: porque un agente que no evalúas sobre casos límite reales no sabes si funciona en producción.
¿Qué pasa cuando la conversación se desvía del guion?
En una demo, el flujo conversacional está controlado. El evaluador hace las preguntas en orden, no interrumpe, no cambia de tema a mitad, no comete errores tipográficos. Los usuarios reales no.
Los usuarios reales hacen preguntas en mitad de un proceso, corrigen lo que dijeron antes, añaden información que el agente ya no puede usar correctamente porque el contexto se llenó, o simplemente preguntan algo que el agente no sabe cómo categorizar. Cada uno de esos desvíos es un punto en el que el agente puede acertar o fallar. Y la suma de esos puntos es lo que determina la fiabilidad real, no el resultado de una conversación ideal.
¿Acumula errores el agente a lo largo del agent loop?
Un agente que ejecuta tres pasos en secuencia puede fallar en el paso tres aunque los pasos uno y dos fueran correctos. O puede llegar al paso tres con un contexto ligeramente incorrecto acumulado en los pasos anteriores —una referencia equivocada, un parámetro mal recuperado, una asunción incorrecta— y generar un resultado final erróneo que parece coherente pero no lo es.
Esto es especialmente grave porque el error compuesto es difícil de detectar sin trazabilidad. Si no tienes un sistema de trace que te permita ver paso a paso qué hizo el agente en cada interacción, no puedes distinguir si el fallo fue en el paso uno, en el tres, o en la acumulación de los tres. Solo ves el resultado final: el cliente insatisfecho.
¿Cómo se evalúa de verdad la fiabilidad de un agente de IA?
Esto es lo que separa un equipo que ha desplegado agentes en producción real de uno que todavía está en fase de demo. La evaluación de la fiabilidad de un agente de IA no es una lista de checks; es un proceso continuo que tiene que empezar antes del despliegue y no terminar nunca.
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Define qué cuenta como éxito antes de medir nada
El primer error de evaluación es medir sin haber definido qué es resolver correctamente un caso. No es lo mismo "el agente dio una respuesta" que "el agente resolvió el caso según la política y el cliente no tuvo que escalar". Antes de correr ningún benchmark, necesitas una definición precisa de éxito para cada tipo de caso que el agente va a manejar.
Sin esa definición, cualquier métrica que saques no te dice nada útil. Un Pass^1 del 90% sobre una definición de éxito laxa puede ser un Pass^1 del 60% sobre una definición de éxito rigurosa que incluya la aplicación correcta de políticas.
Construye un conjunto de evaluación con casos reales, incluidos los límite
El conjunto de evaluación es la base de todo lo demás. Tiene que incluir:
- Casos típicos que el agente va a ver el 70% de las veces. Son los más fáciles y sirven de baseline.
- Casos con ambigüedad donde la política no es completamente clara o el usuario da información incompleta.
- Casos límite donde se cruzan dos políticas, la solicitud tiene una excepción, o el usuario cambia de petición a mitad de la conversación.
- Casos de estrés con errores tipográficos, lenguaje coloquial, cambios de idioma dentro de la misma conversación.
Si tu conjunto de evaluación solo tiene casos típicos, el Pass^k que saques va a ser artificialmente alto. Los casos límite son donde el agente muestra su fiabilidad real.
Mide Pass^k, no solo Pass^1
Ejecuta cada caso del conjunto de evaluación varias veces de forma independiente. No toques el agente entre ejecuciones. Registra cuántas veces resuelve correctamente el mismo caso. Eso te da Pass^k para ese caso concreto.
Cuando tienes Pass^k para todos los casos, puedes calcular el Pass^k global del agente y, lo que es más útil, identificar qué tipos de casos tienen Pass^k más bajo. Ahí es donde tienes que trabajar: en reducir la inconsistencia sobre los casos donde el agente ya casi siempre acierta pero no siempre. Esos son los que más daño hacen en producción porque pasan desapercibidos hasta que acumulan suficientes fallos.
Revisa las trazas, no solo los resultados
Un resultado correcto puede venir de un proceso incorrecto. Un agente que llega a la respuesta correcta por el camino equivocado es un agente que va a fallar en cuanto el camino equivocado lleve a algún sitio diferente. La revisión de traces —la secuencia completa de pasos, tool calls, razonamientos intermedios y respuestas— es imprescindible para entender la fiabilidad real, no solo la fiabilidad aparente.
Implementa logging detallado desde el primer día. Si no puedes ver qué hizo el agente paso a paso en cada interacción, no puedes evaluar su fiabilidad; solo puedes medir su tasa de éxito aparente, que es algo muy diferente.
Evalúa de forma continua, no solo antes del lanzamiento
La evaluación pre-lanzamiento te dice si el agente es apto para producción en el momento del despliegue. No te dice si lo seguirá siendo en dos meses, cuando las políticas cambien, cuando el catálogo de productos se actualice, cuando el modelo base del proveedor se actualice silenciosamente. La evaluación continua —correr el conjunto de evaluación de forma periódica, añadir casos nuevos basados en fallos reales— es lo que convierte una buena arquitectura inicial en un sistema fiable a largo plazo.
¿Qué preguntar a tu proveedor antes de contratar?
Si estás evaluando proveedores de agentes de IA para tu empresa, estas son las preguntas que separan a los que saben de los que venden humo:
¿Cómo miden la fiabilidad de sus agentes? Si la respuesta es solo "precisión" o "tasa de resolución en demos", hay un problema. La precisión en una evaluación puntual no es lo mismo que la consistencia en producción. Un proveedor que entiende la fiabilidad habla de evaluación continua, de casos límite, de Pass^k aunque no use ese nombre exacto.
¿Tienen un proceso de evaluación sobre casos límite y políticas de dominio? La evaluación sobre casos típicos es fácil. Lo difícil —y lo relevante— es cómo se comporta el agente cuando dos políticas se contradicen, cuando el cliente da información incompleta, o cuando la solicitud es legítima pero inusual. Si el proveedor no evalúa sobre esos casos, no sabe cómo se va a comportar el agente cuando aparezcan en producción. Y van a aparecer.
¿Qué nivel de observabilidad ofrecen sobre el agent loop? Tienes que poder ver qué hizo el agente en cada interacción. Cada tool call, cada decisión, cada paso del razonamiento. Sin trazabilidad, no puedes diagnosticar fallos; solo puedes constatar que el cliente no quedó satisfecho.
¿Cómo manejan las actualizaciones del modelo base? Si el agente corre sobre un LLM de terceros —OpenAI, Anthropic, Google— ese modelo se actualiza. A veces sin previo aviso. Esas actualizaciones pueden cambiar el comportamiento del agente de formas sutiles que no aparecen en los logs hasta que acumulan suficientes incidencias. Un proveedor serio tiene un proceso para detectar y gestionar esos cambios.
¿Cómo se comporta el agente cuando la herramienta falla? Las APIs externas fallan. Los timeouts ocurren. Los formatos de respuesta cambian. ¿Tiene el agente un mecanismo de retry con backoff? ¿Sabe escalar al agente humano cuando no puede completar el task? ¿O simplemente devuelve un error que el cliente ve en pantalla?
¿Cómo impacta la fiabilidad en las métricas de negocio?
Esto es lo que importa al final del día: no el Pass^k en abstracto, sino lo que la inconsistencia le cuesta a tu negocio.
Un agente que resuelve bien el 70% de los casos no solo genera un 30% de insatisfacción directa. Genera algo peor: desconfianza sistemática. Los clientes que han tenido una mala experiencia con el agente aprenden a pedirle un humano directamente, aunque el agente podría haberles ayudado. El volumen de escalaciones sube. El coste por interacción sube. El CSAT general baja. Y el agente, que se implantó para ahorrar coste y mejorar experiencia, acaba siendo una capa adicional de fricción.
La tasa de resolución en primer contacto (FCR, First Contact Resolution) es la métrica de negocio que más se correlaciona con la fiabilidad técnica del agente. No la tasa de respuesta, no el tiempo de handling: la tasa de resolución. Un agente que responde rápido pero no resuelve no mejora el FCR. Un agente que resuelve de forma consistente —Pass^k alto— sí lo hace.
El CSAT (Customer Satisfaction Score) responde a la misma lógica. La satisfacción del cliente no viene de que el agente sea rápido, viene de que resuelve. Y de que resuelve de la misma forma, con la misma calidad, independientemente de si es lunes a las diez de la mañana o domingo a medianoche. La consistencia es lo que convierte un buen agente en un activo fiable.
Cuando GuruSup despliega agentes de IA en atención al cliente, la primera métrica que miramos no es el tiempo de respuesta. Es la tasa de resolución autónoma sin escalación, medida durante las primeras semanas en producción real, sobre casos reales, comparada con la línea base del conjunto de evaluación. Si la tasa en producción se aleja significativamente del Pass^k que medimos en evaluación, hay algo en el agente o en las políticas que hay que corregir.
¿Qué diferencia a un agente fiable de uno que simplemente hace buenas demos?
La diferencia no está en el modelo base. Está en el sistema completo.
Un agente fiable tiene evaluación continua sobre un conjunto de casos que incluye los casos límite reales de ese dominio. No solo los casos fáciles que hacen que los números queden bien.
Un agente fiable tiene políticas de dominio explícitas y evaluadas. No instrucciones genéricas que el agente interpreta libremente, sino políticas concretas, probadas sobre casos reales, con evidencia de que el agente las aplica de forma consistente.
Un agente fiable tiene trazabilidad completa. Cada interacción deja un rastro que permite diagnosticar qué pasó, por qué pasó y cómo corregirlo. Sin trazabilidad, los fallos son invisibles hasta que ya han generado suficiente daño.
Un agente fiable tiene mecanismos de degradación controlada: sabe cuándo no sabe, sabe cuándo escalar, sabe cuándo pedir más información en lugar de asumir. El comportamiento ante la incertidumbre es tan importante como el comportamiento en los casos que conoce bien.
Y un agente fiable se evalúa sobre Pass^k, no solo sobre Pass^1. Porque lo que importa no es si funciona en la demo. Es si sigue funcionando el martes siguiente, sobre el mismo tipo de caso, con un cliente diferente, cuando el equipo técnico no está mirando.
Fiabilidad en sistemas multiagente: el problema se multiplica
Hasta ahora hemos hablado de un único agente. En la práctica, muchas empresas están desplegando arquitecturas con varios agentes que se coordinan: un agente de entrada que clasifica la solicitud, un agente especializado que la resuelve, un agente de supervisión que revisa la respuesta antes de enviarla. Los sistemas multiagente tienen ventajas reales —especialización, paralelismo, separación de responsabilidades— pero tienen un efecto colateral sobre la fiabilidad que hay que entender antes de escalar.
Si un agente aislado tiene un Pass^k del 85% sobre un tipo de tarea, y ese agente es el paso 2 de un pipeline de tres agentes donde cada uno tiene su propio Pass^k, la fiabilidad del sistema completo no es el 85% del agente más débil. Es el producto de las fiabilidades individuales. Tres agentes con un 90% de consistencia cada uno producen un sistema con una fiabilidad combinada que se acerca al 73%. Y eso asumiendo que los fallos de cada agente son independientes entre sí, lo que en la práctica no siempre es así: cuando el agente de clasificación comete un error, el agente especializado recibe un contexto incorrecto y la probabilidad de fallo en ese segundo paso sube.
Esto no es un argumento contra los sistemas multiagente. Es un argumento para entender la fiabilidad a nivel de sistema, no solo a nivel de agente individual. Cuando evalúas Pass^k en un sistema multiagente, tienes que medir el sistema completo end-to-end, no cada agente por separado, porque la composición de agentes genera comportamientos emergentes que no se pueden predecir evaluando cada pieza en aislamiento.
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
¿Qué prácticas mejoran la fiabilidad en sistemas multiagente?
La definición clara de responsabilidades entre agentes es el primer paso. Cada agente tiene que tener un scope delimitado y la interfaz entre agentes —qué información pasa de uno a otro, en qué formato, con qué garantías— tiene que estar especificada y evaluada. Las interfaces ambiguas son fuentes de inconsistencia que no aparecen en la evaluación individual pero sí en la evaluación end-to-end.
Los mecanismos de validación en cada paso del pipeline reducen el impacto de los errores que se propagan. Si el agente de clasificación puede marcar su salida como de baja confianza, el agente receptor puede tratar ese caso de forma diferente —pidiendo confirmación, escalando directamente— en lugar de procesar como si la clasificación fuera segura.
La evaluación end-to-end con casos reales es imprescindible. En un sistema multiagente, la prueba unitaria de cada agente no sustituye la prueba del sistema completo. Las interacciones entre agentes producen fallos que solo se ven cuando el sistema funciona como un todo.
El problema específico de los agentes en atención al cliente
La atención al cliente tiene un conjunto de características que hacen que la fiabilidad sea especialmente crítica y especialmente difícil de garantizar. No porque los agentes de IA no puedan hacerlo bien —pueden, y muchas empresas lo están consiguiendo— sino porque el contexto tiene una complejidad inherente que hay que entender para evaluarla correctamente.
La variabilidad del usuario es máxima. En atención al cliente, los usuarios no tienen formación para interactuar con el sistema. Escriben como hablan, mezclan peticiones en el mismo mensaje, dan información incompleta, cambian de petición a mitad de la conversación. Un agente que se evalúa solo sobre prompts bien formados no ha sido evaluado sobre el input real que va a recibir.
Las políticas son específicas, complejas y cambian. Las políticas de devolución, garantía, escalación, descuento o información que puede compartirse con el cliente son específicas de cada empresa, tienen excepciones, se actualizan con frecuencia y a veces se contradicen entre sí en casos límite. Un agente que aplica las políticas bien la semana del despliegue puede aplicarlas mal dos meses después si las políticas se actualizaron y el agente no. La evaluación continua detecta ese drift antes de que acumule suficiente daño.
El coste de fallo es asimétrico. En muchos dominios, un error del agente tiene un coste bajo. En atención al cliente, un error puede resultar en un cliente perdido, una reclamación pública, o una acción que el agente no tenía autorización para ejecutar. El umbral de fiabilidad aceptable en atención al cliente es significativamente más alto que en un chatbot de captación o en un buscador interno.
El canal condiciona el comportamiento. Un mismo agente se comporta de forma diferente en chat, en WhatsApp, en email o en agentes de voz IA. El formato de la conversación, la longitud de los turnos, la velocidad esperada de respuesta y la tolerancia del usuario a las demoras cambian según el canal. Un agente evaluado en chat puede tener comportamientos diferentes cuando se despliega en WhatsApp con exactamente las mismas instrucciones. La evaluación tiene que contemplar los canales reales donde va a operar el agente.
¿Cómo afecta la base de conocimiento a la fiabilidad?
Una parte significativa de los fallos de agentes en atención al cliente no viene del modelo ni del agent loop: viene de la base de conocimiento. Un agente de IA para soporte que consulta una base de conocimiento desactualizada, mal estructurada o con información contradictoria va a generar respuestas inconsistentes aunque el modelo y el pipeline sean perfectos. La fiabilidad del agente depende de la fiabilidad de la información que consume.
Esto tiene una implicación práctica importante: cuando diagnostiques fallos de consistencia, no asumas que el problema está en el agente. Revisa también la base de conocimiento. ¿Tiene entradas duplicadas con información diferente sobre el mismo tema? ¿Hay políticas antiguas que no se eliminaron cuando se actualizaron? ¿Las respuestas están formuladas de forma que el agente pueda recuperarlas y aplicarlas correctamente, o están escritas para un humano que hace búsqueda manual?
La relación entre la calidad de la base de conocimiento con IA y la fiabilidad del agente es directa. Mejorar la base de conocimiento es frecuentemente la intervención con mejor relación coste-impacto cuando un agente empieza a fallar de forma sistemática en un dominio concreto.
¿Cuánta fiabilidad es suficiente?
Esta es la pregunta que evita casi todo el mundo porque no tiene una respuesta universal. Pero sí tiene una respuesta práctica.
El umbral de fiabilidad suficiente depende de dos variables: el coste del fallo y el volumen de casos. Ambas en conjunto determinan cuántos fallos reales produce el agente al mes. Un agente que atiende 10.000 conversaciones al mes con un Pass^k del 85% va a producir 1.500 fallos al mes. Si cada fallo es una respuesta subóptima en una pregunta de bajo impacto, 1.500 fallos al mes es manejable. Si cada fallo es una devolución incorrectamente denegada o una promesa que el sistema no puede cumplir, 1.500 fallos al mes es una crisis de producto.
Antes de desplegar un agente, define cuál es el coste real de un fallo en tu caso concreto. No en abstracto: en euros, en clientes perdidos, en NPS, en escalaciones. Eso te da el umbral de Pass^k mínimo aceptable para ese tipo de tarea. Y si el agente no lo alcanza en evaluación, tienes que mejorar la arquitectura antes de desplegar, no después.
También hay que distinguir entre tipos de fallo. No todos los fallos de un agente tienen el mismo coste. Un agente puede tener un Pass^k bajo sobre casos de baja criticidad —preguntas frecuentes simples— y un Pass^k alto sobre casos de alta criticidad —gestión de reclamaciones, devoluciones, escalaciones—. Si puedes segmentar la evaluación por criticidad y asegurarte de que el Pass^k es más alto donde el coste de fallo es más alto, tienes una arquitectura de fiabilidad diferenciada que es tanto más eficiente que un número único de fiabilidad global.
Fiabilidad aceptable vs fiabilidad gestionada
Hay una diferencia entre declarar que un nivel de fiabilidad es "aceptable" y tener un sistema para gestionarlo activamente. La fiabilidad aceptable es un umbral: por encima, el agente opera; por debajo, hay que intervenir. La fiabilidad gestionada es un proceso: mides continuamente, detectas caídas antes de que sean visibles en el negocio, tienes un protocolo de corrección, vuelves a medir.
La mayoría de los equipos que despliegan agentes de IA hoy tienen a lo sumo fiabilidad aceptable. Muy pocos tienen fiabilidad gestionada. Y la diferencia es exactamente la que separa a las empresas donde el agente sigue funcionando bien dos años después del despliegue de las que a los seis meses tienen que reemplazarlo o volver a los agentes humanos para cubrir lo que el sistema automatizado no resuelve.
En GuruSup, cuando desplegamos agentes de IA para atención al cliente en empresas, la conversación sobre fiabilidad empieza en el diseño de la arquitectura, no después del lanzamiento. Definimos el umbral, construimos el conjunto de evaluación, medimos Pass^k antes del go-live, y configuramos la evaluación continua para detectar drift antes de que llegue al cliente.
¿Qué hacer si ya tienes un agente desplegado que falla?
Antes de cambiar de proveedor o de modelo, diagnostica. La mayoría de las veces el problema no es el modelo: es la evaluación que nunca se hizo bien, las políticas que nadie revisó después del despliegue, o las herramientas que empezaron a comportarse de forma diferente y nadie detectó el cambio.
Paso 1: construye un conjunto de evaluación con los fallos reales. Coge las últimas semanas de interacciones que acabaron en escalación o en CSAT bajo. Esos son tus casos de evaluación. No los inventados para la demo.
Paso 2: mide Pass^k sobre esos casos. Ejecuta los casos varias veces y mide la consistencia. Identifica los tipos de casos donde el Pass^k es más bajo. Ahí está el problema.
Paso 3: traza los fallos a su origen. Para cada tipo de caso con Pass^k bajo, revisa las trazas. ¿Falla el agente en el tool call? ¿En la interpretación de la política? ¿En el manejo de un caso límite? ¿En la acumulación de errores a lo largo del agent loop? Cada origen tiene una solución diferente.
Paso 4: corrige, evalúa, repite. La mejora de la fiabilidad de un agente es un proceso iterativo, no un proyecto con fecha de entrega. Cada corrección requiere una nueva evaluación. Cada nueva evaluación revela nuevos casos que mejorar.
Si en el paso 3 descubres que el origen del fallo es sistemático y no específico de un tipo de caso —que el agente simplemente no aplica bien las políticas o no sabe usar las herramientas de forma consistente— entonces sí tiene sentido revisar la arquitectura o el proveedor. Pero ese diagnóstico requiere datos, no intuición.
Preguntas frecuentes sobre fiabilidad y evaluación de agentes de IA
¿Qué es Pass^k y por qué importa más que Pass^1? Pass^1 mide si el agente completa con éxito una tarea en un intento concreto. Pass^k mide la consistencia: si el agente completa la misma tarea correctamente en k intentos independientes. En producción, lo que importa es Pass^k, porque el agente va a atender el mismo tipo de caso cientos de veces. Un agente con Pass^1 alto pero Pass^k bajo parece bueno en demos pero falla con frecuencia en producción.
¿Qué es tau-bench? tau-bench es un benchmark desarrollado por Sierra Research (arXiv:2406.12045) para evaluar agentes de IA que usan herramientas reales y aplican políticas de dominio en conversaciones con usuarios simulados. Es uno de los marcos de evaluación más relevantes para agentes de atención al cliente porque replica el escenario real: tool use, políticas de negocio, conversación no controlada. Usa Pass^k como métrica de consistencia.
¿Por qué mi agente funciona en la demo pero falla en producción? La demo es un entorno controlado: casos típicos, flujo conversacional ordenado, evaluador que sigue el guion. La producción tiene variabilidad real: usuarios que no explican bien lo que quieren, casos límite, herramientas que fallan, políticas que se solapan. Un agente evaluado solo en demos no ha demostrado su fiabilidad en las condiciones que realmente importan. El gap entre demo y producción es, en esencia, el gap entre Pass^1 y Pass^k.
¿Qué métricas de negocio se ven afectadas por la inconsistencia del agente? La tasa de resolución en primer contacto (FCR) es la más directamente afectada. También el CSAT, la tasa de escalaciones y, en última instancia, el coste por interacción. Un agente inconsistente genera escalaciones evitables, reduce la confianza del cliente en el canal automatizado y acaba aumentando la carga sobre los agentes humanos.
¿Qué es la trazabilidad y por qué la necesito? La trazabilidad es el registro completo de cada paso que da el agente en una interacción: qué tool call hizo, qué respuesta recibió, cómo interpretó esa respuesta, qué decidió hacer después. Sin trazabilidad, cuando un caso falla solo sabes que falló. Con trazabilidad, sabes dónde y por qué. Es imprescindible para diagnosticar y mejorar la fiabilidad de un agente en producción.
¿Las alucinaciones afectan a la fiabilidad del agente? Sí, pero no son la única fuente de inconsistencia. Un agente puede fallar sin alucinar: eligiendo la herramienta equivocada, malinterpretando la política, acumulando errores en el agent loop. Las alucinaciones son un tipo específico de fallo —el modelo genera información que no existe— pero la fiabilidad de un agente abarca todos los tipos de fallo, no solo ese.
---
La fiabilidad de un agente de IA no se demuestra en una sala de reuniones. Se demuestra en producción, sobre casos reales, con métricas que van mucho más allá del Pass^1 de la demo. Si tu agente falla más de lo que debería —o si aún no has medido cuánto falla de verdad— el primer paso no es cambiar de proveedor. Es construir el conjunto de evaluación, medir Pass^k sobre casos reales, y diagnosticar dónde se origina la inconsistencia.
Nosotros llevamos tiempo haciendo exactamente eso para empresas que necesitan agentes que funcionen en producción real, no solo en la presentación de ventas. Si quieres saber cómo lo hacemos, cuéntanos tu caso y empezamos por donde toca: midiendo lo que de verdad importa.