Alucinaciones de la IA: qué son y cómo evitarlas
Qué son las alucinaciones de la inteligencia artificial, por qué ocurren aunque el modelo sea potente y cómo evitar que tu agente IA le dé datos inventados a un cliente.
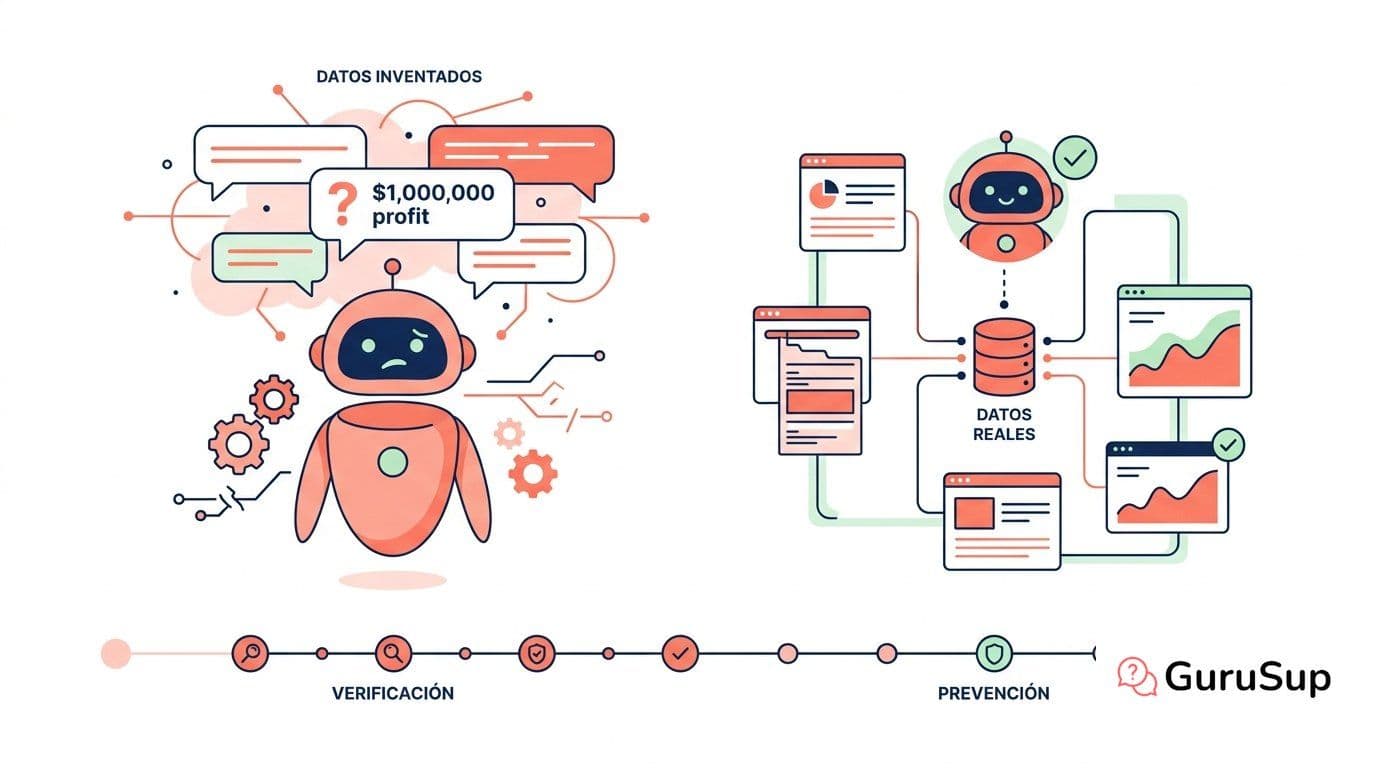
Tabla de contenidos
- ¿Qué son las alucinaciones de la inteligencia artificial?
- ¿Por qué ocurren? El LLM predice tokens, no consulta verdad
- ¿Por qué no desaparecen aunque el modelo mejore?
- ¿Cómo se mitigan las alucinaciones de la inteligencia artificial?
- El riesgo real para tu empresa: más allá del dato incorrecto
- ¿Cómo lo controlamos en GuruSup?
- Preguntas frecuentes sobre las alucinaciones de la inteligencia artificial
Tu agente de IA atiende a un cliente que pregunta por el precio de un servicio. El agente responde con total seguridad, con el tono correcto y en perfecto castellano. Solo hay un problema: esa cifra no existe en ningún sitio. El agente se la ha inventado.
Eso es una alucinación de inteligencia artificial, y si estás pensando en desplegar un agente de IA en tu empresa, es lo primero que tienes que entender a fondo. No porque sea un defecto que se va a arreglar en la próxima versión del modelo, sino porque es una característica estructural de cómo funcionan estos sistemas. Y porque la diferencia entre un agente que alucina y uno que no te da problemas no está en el modelo que eliges, sino en cómo está construido lo que hay alrededor.
¿Qué son las alucinaciones de la inteligencia artificial?
Las alucinaciones de la inteligencia artificial son respuestas que un modelo de lenguaje genera con aparente confianza, pero que no están respaldadas por ningún dato real, documento fuente ni hecho verificable. El modelo no miente deliberadamente ni tiene intención de engañar; simplemente no puede saber que se está equivocando.
La clave está en entender qué hace un LLM (Large Language Model) cuando genera texto: predice el siguiente token —la siguiente palabra o fragmento de palabra— en función de todo lo que ha visto antes, incluyendo lo que ya lleva escrito en esa misma respuesta. No consulta ninguna base de datos de hechos verdaderos. No tiene acceso a la realidad. Calcula estadísticamente qué viene a continuación dado el contexto, y esa predicción estadística es el único mecanismo que tiene. A veces ese mecanismo produce texto factualmente correcto. A veces produce texto plausible, bien construido y completamente falso.
Por eso las alucinaciones en IA no son un fallo puntual: son el resultado predecible de una arquitectura que maximiza la coherencia textual, no la veracidad.
¿Por qué ocurren? El LLM predice tokens, no consulta verdad
Para entender el problema de fondo hay que meterse un momento en cómo se entrena un LLM. Durante el entrenamiento, el modelo procesa cantidades masivas de texto y aprende a predecir qué palabra sigue a cada secuencia. No aprende proposiciones del tipo "esto es verdad / esto es falso"; aprende distribuciones estadísticas sobre cómo suele combinarse el lenguaje.
Esto tiene tres consecuencias directas en las alucinaciones de la inteligencia artificial:
Primera: el modelo no sabe lo que no sabe. Si le preguntas algo que no está en sus datos de entrenamiento o que quedó mal representado en ellos, no te dice "no lo sé". Genera la respuesta más probable dado el contexto, que puede ser completamente inventada pero estadísticamente coherente.
Segunda: el modelo prioriza la fluidez sobre la verdad. Su objetivo de entrenamiento era producir texto que pareciera escrito por humanos, no texto factualmente correcto. Una respuesta fluida y segura "suena mejor" desde la perspectiva del modelo aunque sea falsa.
Tercera: el modelo puede reforzar sus propios errores. Cuando genera texto paso a paso, cada token que escribe pasa a ser parte del contexto para el siguiente. Si comete un error de hecho en la primera frase, las siguientes frases construyen sobre ese error como si fuera válido. El desliz inicial se convierte en la premisa del párrafo entero.
Los tipos de alucinaciones que debes conocer
No todas las alucinaciones son iguales. Distinguir entre ellas ayuda a diseñar mejor las defensas:
Alucinaciones factuales. El modelo afirma hechos incorrectos: una fecha que no existe, una estadística inventada, una ley que no está en vigor. Son las más peligrosas en atención al cliente porque el cliente puede tomar decisiones basándose en esa información.
Alucinaciones de fuente. El modelo cita una fuente real —un estudio, un artículo, un informe— pero el contenido que atribuye a esa fuente no corresponde a lo que dice. O directamente inventa la referencia con un título plausible.
Alucinaciones intrínsecas. La respuesta contradice directamente el contexto o documento que el propio modelo tiene delante. El documento dice "el plazo es 30 días" y el modelo responde "el plazo es 15 días". Pasa más de lo que parece, especialmente cuando el contexto es largo.
Alucinaciones extrínsecas. La respuesta no contradice el documento, pero tampoco está respaldada por él. El modelo añade información extra —que suena coherente— que simplemente no está en ningún sitio.
¿Por qué no desaparecen aunque el modelo mejore?
Hay un malentendido extendido: "los modelos más nuevos alucinan menos, así que en algún momento el problema desaparecerá". Es verdad que los modelos más recientes tienen tasas de hallucination más bajas en benchmarks estándar. Pero no es verdad que vayan a llegar a cero, y menos en contextos empresariales específicos.
La razón es estructural. El mecanismo de predicción de tokens no desaparece aunque se escale el modelo. Lo que mejora es la calibración —el modelo aprende a no inventar cuando no está seguro en casos comunes— pero en dominios específicos, con terminología de empresa, precios reales o políticas internas, el modelo no tiene ese entrenamiento previo y las alucinaciones regresan.
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Además, hay un segundo factor: cuanto más largo es el contexto, mayor es el riesgo. Cuando le pasas al modelo cien páginas de documentación interna para que responda una pregunta, la probabilidad de que pierda el hilo, confunda apartados o genere una respuesta que mezcla información de distintas partes aumenta considerablemente. Es el fenómeno conocido como "lost in the middle": los modelos prestan menos atención a la información que cae en la parte central de un contexto muy largo.
El problema no se resuelve esperando a que salga una versión nueva del modelo. Se resuelve diseñando el sistema que rodea al modelo.
¿Cómo se mitigan las alucinaciones de la inteligencia artificial?
Aquí está el núcleo del asunto. Ninguna técnica elimina las alucinaciones al 100%, pero la combinación correcta las reduce a un nivel manejable en producción. Estas son las capas que importan:
RAG y grounding: anclar el modelo a tus documentos reales
La técnica más efectiva para agentes empresariales es el RAG (Retrieval-Augmented Generation). En lugar de que el modelo genere una respuesta desde su "memoria" de entrenamiento —que puede estar desactualizada o no contener tu información específica— el sistema recupera primero los fragmentos de documentación relevantes y se los pasa al modelo como contexto explícito antes de generar la respuesta.
El resultado es que el modelo tiene delante el texto exacto del que debe partir. No puede inventarse el precio de un servicio si el precio está literalmente en el párrafo que tiene como contexto. Esto se llama grounding: el modelo está "anclado" a fuentes reales y verificables.
El grounding no elimina las alucinaciones —el modelo todavía puede interpretar mal lo que lee o mezclar información de distintos fragmentos— pero reduce drásticamente los casos en los que el modelo opera en el vacío. Si quieres entender cómo funciona por dentro, en nuestra guía de qué es RAG explicamos la arquitectura completa.
Guardrails: el sistema de límites que el modelo necesita
Los guardrails son capas de control que actúan antes, durante o después de la generación del modelo. En la práctica pueden ser:
- Filtros de entrada que detectan preguntas fuera del alcance del agente y las redirigen a un humano antes de que el modelo intente responderlas.
- Validadores de salida que comparan la respuesta generada contra los documentos fuente y marcan discrepancias antes de que la respuesta llegue al usuario.
- Reglas de negocio explícitas que el sistema aplica independientemente de lo que el modelo genere: si el modelo dice un precio, el sistema lo verifica contra la base de datos antes de mostrarlo.
Los guardrails no son una red de seguridad de último recurso; son parte del diseño del agente de IA para atención al cliente desde el primer día. Un agente sin guardrails bien configurados no es un agente de producción.
Temperatura: menos creatividad, menos invención
El parámetro de temperatura controla cuánta aleatoriedad introduce el modelo al elegir entre los tokens posibles. A temperatura alta, el modelo es más "creativo" y variado; a temperatura baja, más predecible y conservador.
Para agentes empresariales que responden preguntas factuales —precios, políticas, plazos, condiciones de servicio— la temperatura debe ser baja, cerca de cero. No necesitas creatividad: necesitas precisión. Un modelo a temperatura 0 que tiene el dato delante en el contexto va a citarlo correctamente casi siempre. El mismo modelo a temperatura 1 puede parafrasearlo de una forma que lo distorsione.
Es uno de los ajustes más simples y más infrautilizados.
Citaciones y trazabilidad de fuentes
Cuando el agente indica de dónde viene cada dato —"según la sección 3 de tu manual de servicio"— ocurren dos cosas útiles. Primero, el modelo tiene que "decidir" qué fuente está usando, lo que reduce la mezcla de información de distintos documentos. Segundo, el cliente puede verificarlo si quiere, y tú puedes auditarlo cuando algo sale mal.
Las citaciones son también una herramienta de confianza: un agente que muestra sus fuentes da más confianza que uno que afirma cosas sin respaldo aparente. Implementarlas bien requiere que el sistema RAG guarde referencias precisas a los fragmentos recuperados, no solo el texto.
Human-in-the-loop: saber cuándo ceder el paso
Hay preguntas que un agente no debería intentar responder solo. Preguntas con consecuencias legales, reclamaciones complejas, situaciones de cliente muy afectado emocionalmente, casos que están fuera de la documentación disponible. Saber cuándo pasar a un agente humano es parte del diseño del agente, no un fallo del mismo.
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Un sistema bien construido tiene umbrales de confianza: si el retrieval no encuentra documentos relevantes con suficiente similitud semántica, el agente no improvisa, sino que escala. Esto se puede hacer de forma transparente al usuario ("esta pregunta la gestiona directamente uno de nuestros agentes") y mejora tanto la satisfacción del cliente como la tasa de respuestas correctas. Cuando el origen del fallo es sistemático —no puntual— conviene revisar por qué tu agente de IA falla: muchas veces el problema está en la evaluación, no en el modelo.
Validación y evaluación continua
Ninguna de las técnicas anteriores se puede configurar una vez y olvidar. Los documentos cambian, las preguntas evolucionan y aparecen casos de uso que no habías contemplado. Medir la tasa de hallucination en producción —con herramientas como RAGAS o con evaluaciones manuales periódicas— es la única forma de saber si el sistema sigue funcionando bien.
Aquí entra el valor de una buena base de conocimiento para atención al cliente: no solo almacena los documentos, sino que permite mantenerlos actualizados de forma centralizada. Si el precio cambia, el agente lo sabe inmediatamente porque el documento fuente está actualizado; no hay que reentrenar ningún modelo.
El riesgo real para tu empresa: más allá del dato incorrecto
Una alucinación no es solo un error técnico. En el contexto de la atención al cliente tiene consecuencias concretas:
Riesgo reputacional. Un cliente al que tu agente le da un precio inventado y llama para reclamarlo no se va a quedar con el agente: se va a quedar con que tu empresa le mintió. Aunque el error sea del modelo, la responsabilidad ante el cliente es tuya.
Riesgo legal. En sectores regulados —finanzas, seguros, salud, asesorías— dar información incorrecta sobre un producto, una condición de contrato o una normativa puede tener consecuencias que van más allá de la reputación. Una alucinación sobre las condiciones de una póliza o sobre los plazos de un procedimiento administrativo no es solo un error operativo.
Riesgo de erosión de confianza interna. Si los agentes del equipo detectan que el sistema de IA comete errores, dejan de usarlo. Y un agente que nadie usa no ahorra nada.
Estos riesgos no son hipotéticos. En 2023 un abogado presentó en un tribunal federal de Estados Unidos citas de jurisprudencia que había generado ChatGPT. Los casos no existían. El abogado fue sancionado. El cliente, perjudicado. El modelo nunca supo que se había equivocado.
¿Cómo lo controlamos en GuruSup?
En GuruSup construimos agentes de IA para empresas que atienden a clientes reales, con documentación real, sobre preguntas reales. Hemos visto en producción exactamente los escenarios que describimos aquí: agentes que, sin el sistema correcto alrededor, generaban respuestas plausibles y falsas.
Lo que hemos aprendido es que el modelo no es el problema central. Los modelos de hoy son suficientemente buenos. El problema es el sistema que los rodea: cómo se recupera la información (RAG bien diseñado, no un RAG de prueba de concepto), cómo se filtran las preguntas fuera de alcance (guardrails), cómo se monitoriza en producción y cómo se mantiene actualizada la base de conocimiento. Junto al RAG, el prompt engineering bien aplicado es la herramienta más directa para reducir comportamientos impredecibles antes de que lleguen al cliente.
No existe ningún agente que alucine cero. Existe un agente cuyo sistema de control hace que las alucinaciones, cuando ocurren, no lleguen al cliente.
Preguntas frecuentes sobre las alucinaciones de la inteligencia artificial
¿Las alucinaciones de la IA son mentiras deliberadas? No. El modelo no tiene intención, no evalúa si lo que genera es verdad o mentira. Genera el texto estadísticamente más probable dado el contexto. Si ese texto es incorrecto, el modelo no lo sabe.
¿Los modelos más potentes como GPT-4 o Claude dejan de alucinar? Alucinan menos en dominios generales, pero en dominios específicos de empresa —tus precios, tus políticas, tu documentación interna— siguen alucinando si no hay un sistema de grounding que los ancle a esa información.
¿El RAG elimina las alucinaciones? Las reduce drásticamente, pero no las elimina. Un RAG mal implementado —con chunks demasiado grandes, retrieval poco preciso, sin reranking— puede recuperar los fragmentos equivocados y el modelo generará sobre información incorrecta de todas formas. El RAG resuelve el problema cuando está bien construido. Si quieres entender cómo funciona un LLM por dentro antes de hablar de RAG, aquí tienes nuestra guía sobre qué es un LLM.
¿Puedo saber cuándo mi agente está alucinando? No en tiempo real de forma completamente fiable, pero sí puedes implementar validadores de salida que cruzan la respuesta con los documentos fuente, monitorizaciones periódicas de calidad y umbrales de confianza que activen el escalado a humano cuando el retrieval no encuentra contexto relevante.
¿Esto significa que la IA no es fiable para atención al cliente? Significa que la IA no es fiable por sí sola, sin el sistema correcto alrededor. Con RAG bien implementado, guardrails, temperatura controlada y validación continua, un chatbot de atención al cliente puede responder correctamente en la inmensa mayoría de los casos. La clave es no desplegarlo como si fuera infalible.
---
Si estás evaluando montar un agente para tu equipo de atención al cliente y las alucinaciones de la inteligencia artificial son tu principal preocupación, lo que necesitas no es un modelo más potente: necesitas una arquitectura que las contenga. Eso es exactamente lo que construimos.