¿Qué es LlamaIndex? Guía práctica para equipos técnicos
LlamaIndex es el framework de datos para RAG: conecta tus documentos a un LLM en minutos. Te explicamos cómo funciona, en qué se diferencia de LangChain y cuándo usarlo.

Tabla de contenidos
- ¿Para qué sirve LlamaIndex?
- ¿Cómo funciona LlamaIndex por dentro?
- ¿Qué es RAG y por qué LlamaIndex lo hace mejor que hacerlo a mano?
- ¿Cuál es la diferencia entre LlamaIndex y LangChain?
- ¿Cuándo usar LlamaIndex y cuándo no?
- ¿Qué son LlamaHub y LlamaParse?
- ¿Cómo se usa LlamaIndex para atención al cliente con IA?
- Preguntas frecuentes sobre LlamaIndex
Llevas semanas intentando que tu agente de IA responda preguntas sobre la documentación interna de tu empresa. Le das los manuales, las FAQs, los contratos. El modelo los "lee", asiente, y luego te suelta una respuesta que se ha inventado a medias porque no sabe cómo recuperar lo que necesita cuando lo necesita. No es el modelo. No es tu prompt. Es que no tienes la capa de datos.
En GuruSup llevamos años montando agentes de IA que leen bases de conocimiento reales para responder a clientes reales, y si hay una herramienta que aparece en casi todos los stacks de RAG en producción, esa es LlamaIndex. En esta guía te cuento exactamente qué es, cómo funciona por dentro, en qué se diferencia de LangChain y cuándo tiene sentido usarlo en un proyecto de empresa.
¿Para qué sirve LlamaIndex?
LlamaIndex es un framework de datos de código abierto diseñado específicamente para conectar fuentes de datos externas —tus PDFs, bases de datos, APIs, documentos de Word— con modelos de lenguaje de gran tamaño (LLM). Está disponible en Python y TypeScript.
El problema que resuelve es concreto: los LLM saben mucho del mundo en general, pero no saben nada de tu empresa, tu producto ni tus procesos internos. Su conocimiento está congelado en el momento en que fueron entrenados. Puedes darle esa información en el contexto de cada conversación, pero para eso primero tienes que saber qué información darle y cómo estructurarla para que el modelo la use bien.
Eso es LlamaIndex: la capa que se encarga de ingerir tus datos, organizarlos en estructuras que los LLM pueden consultar eficientemente, y devolverle al modelo el contexto exacto que necesita para responder con precisión. No es un orquestador de flujos de trabajo —eso lo hace mejor LangChain—. Es una capa de datos especializada en RAG.
¿Cómo funciona LlamaIndex por dentro?
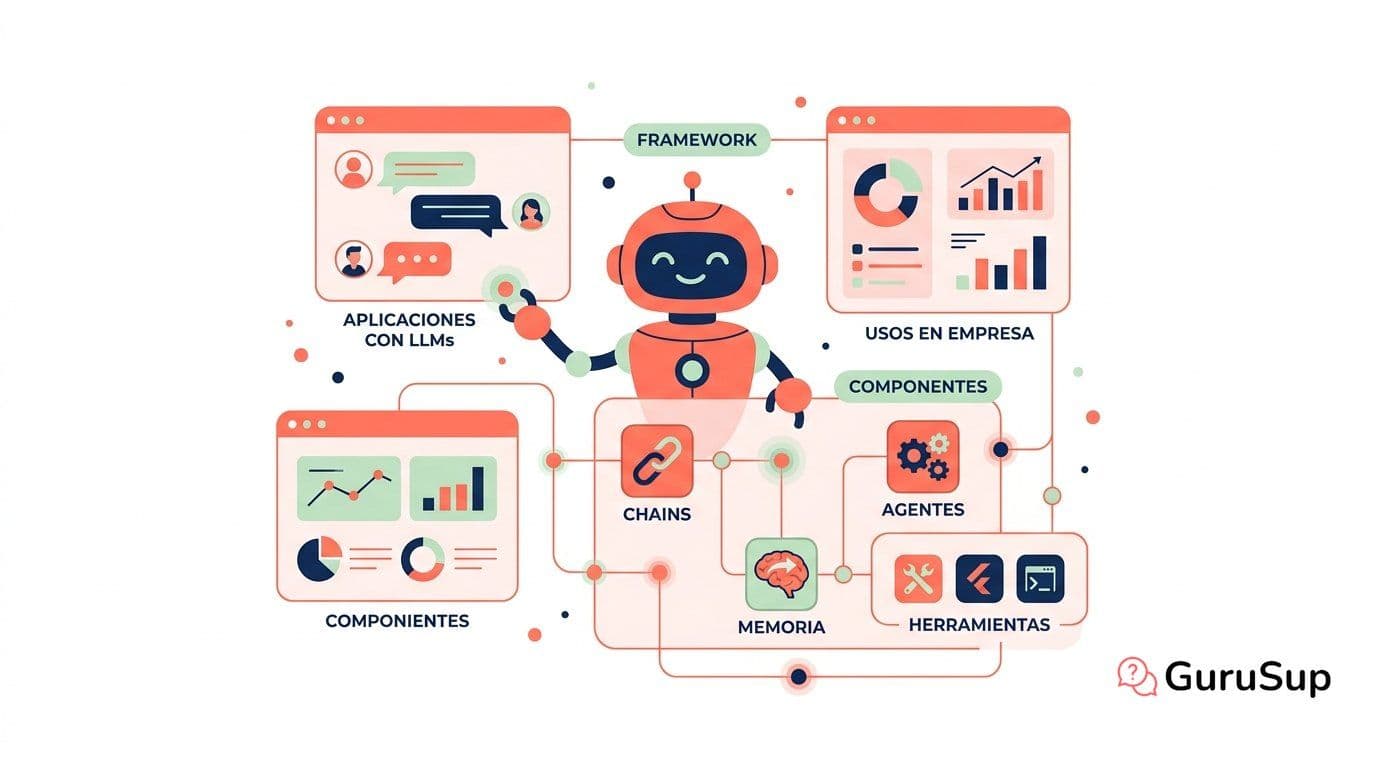
El pipeline de LlamaIndex tiene tres etapas que se encadenan siempre en el mismo orden. Entender las tres es entender por qué funciona.
¿Qué son los data connectors y qué pueden cargar?
El primer problema cuando montas un sistema RAG es que tus datos están en todas partes y en todos los formatos: PDFs escaneados, hojas de cálculo, páginas web, respuestas de APIs, bases de datos SQL. Un LLM no puede leer ninguno de esos formatos directamente.
Los data connectors —también llamados "loaders" en la documentación de LlamaIndex— son los componentes que resuelven exactamente eso. Se conectan a tu fuente de datos en su formato nativo, extraen el contenido y lo convierten en objetos "documento" que LlamaIndex puede procesar. De serie, LlamaIndex incluye un lector que carga cualquier archivo de un directorio local (Markdown, PDF, Word, PowerPoint, imágenes, audio, vídeo). Para todo lo demás —Notion, Google Drive, Slack, bases de datos vectoriales externas, APIs de terceros— existe LlamaHub: un repositorio de más de cien conectores de código abierto.
El resultado de esta etapa es siempre el mismo: una colección de documentos estructurados, con su contenido y sus metadatos, listos para la siguiente fase.
¿Cómo funciona el indexing en LlamaIndex?
Una vez cargados los documentos, LlamaIndex los indexa: los transforma en una representación que permite recuperarlos de forma eficiente cuando llega una consulta. Este paso es el núcleo de lo que hace único a LlamaIndex.
El índice más utilizado es el VectorStoreIndex. El proceso es este: cada documento se divide en chunks (fragmentos), cada chunk se convierte en un embedding —una representación numérica de su significado semántico— y ese embedding se almacena en una base de datos vectorial. Cuando el usuario hace una pregunta, esa pregunta también se convierte en embedding, y el sistema busca los chunks cuyo embedding es más parecido al de la pregunta. No busca por palabras clave: busca por significado.
LlamaIndex también ofrece otros tipos de índice: un índice de resumen (útil para preguntas que requieren sintetizar todo el documento) y un índice de grafo de conocimiento (para datos con relaciones complejas entre entidades). Por defecto, almacena los índices en memoria, pero se integra con bases de datos vectoriales externas como Pinecone, Weaviate o Chroma para persistencia a escala.
¿Qué hace un query engine de LlamaIndex?
El query engine es la interfaz por la que el usuario interactúa con los datos indexados. Toma una pregunta en lenguaje natural y devuelve una respuesta enriquecida con el contexto recuperado. Por dentro, ocurren tres cosas en secuencia:
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Primero, recuperación: el query engine convierte la pregunta en embedding, busca los chunks más relevantes en el índice y los trae.
Segundo, postprocesamiento: los chunks recuperados pueden reordenarse, filtrarse o transformarse antes de pasárselos al modelo. Aquí es donde entra el reranking, que mejora mucho la calidad de las respuestas pero que casi ningún tutorial menciona.
Tercero, síntesis: el contexto recuperado más la pregunta original se combinan en un prompt y se envían al LLM, que genera la respuesta final.
LlamaIndex ofrece varios tipos de query engine para distintos casos: para datos JSON, para text-to-SQL (preguntar sobre bases de datos relacionales en lenguaje natural), para comparar múltiples índices al mismo tiempo.
¿Qué es RAG y por qué LlamaIndex lo hace mejor que hacerlo a mano?
RAG —Retrieval-Augmented Generation— es el patrón que resuelve la limitación de conocimiento estático de los LLM. En lugar de intentar que el modelo "sepa" tu información (lo que requeriría reentrenarlo, que es caro y lento), se la das en el contexto de cada respuesta: primero recuperas los fragmentos relevantes de tu base de conocimiento, luego se los pasas al modelo junto con la pregunta.
Implementar RAG a mano significa gestionar la carga de documentos, el chunking, la generación de embeddings, la base de datos vectorial, la búsqueda semántica, el reranking y la síntesis de respuesta. Cada pieza tiene su propia lógica, sus propios errores posibles y su propio mantenimiento.
LlamaIndex proporciona abstracciones probadas en producción para cada uno de esos pasos, con integraciones directas a los modelos de embeddings más usados (OpenAI, HuggingFace, Cohere) y a las bases de datos vectoriales más populares. La diferencia entre hacerlo a mano y usar LlamaIndex es la diferencia entre implementar autenticación desde cero o usar una librería de OAuth: puedes hacerlo sin ella, pero no tiene mucho sentido.
El otro motivo por el que LlamaIndex destaca en RAG es su sistema de evaluación nativo. Incluye herramientas para medir faithfulness (¿la respuesta se ciñe al contexto recuperado o se inventa cosas?), correctness (¿coincide con la respuesta esperada?) y relevancy (¿el contexto recuperado es pertinente para la pregunta?). En la mayoría de stacks RAG en español, esta parte se omite. Es un error: sin métricas, no sabes si tu sistema funciona o solo lo parece.
¿Cuál es la diferencia entre LlamaIndex y LangChain?
Esta es la pregunta que más aparece cuando alguien empieza a construir con LLM, y la respuesta que te dan casi siempre es vaga. Aquí va una versión clara:
LlamaIndex es una capa de datos. LangChain es una capa de orquestación.
LlamaIndex está optimizado para una cosa: ingerir datos, indexarlos y recuperarlos bien. Tiene más tipos de índice, más opciones de recuperación avanzada, mejor soporte para chunking jerárquico y evaluación de RAG integrada. Si tu problema principal es "necesito que mi agente responda bien sobre mis documentos", LlamaIndex es el especialista.
LangChain está orientado a encadenar llamadas a LLM, conectar herramientas externas y orquestar flujos de trabajo complejos. Tiene más integraciones con APIs de terceros, mejor soporte para cadenas de razonamiento multipaso y un ecosistema más amplio para construir agentes generales.
- Especialidad — LlamaIndex: Datos, indexing, retrieval · LangChain: Orquestación, flujos LLM
- RAG — LlamaIndex: Nativo y optimizado · LangChain: Posible, pero más manual
- Tipos de índice — LlamaIndex: Múltiples y especializados · LangChain: Básicos
- Evaluación de RAG — LlamaIndex: Nativa · LangChain: Requiere librerías externas
- Agentes generales — LlamaIndex: Posible, no es su fuerte · LangChain: Nativo
- Curva de aprendizaje — LlamaIndex: Más accesible para datos · LangChain: Más compleja
En producción, muchos equipos usan los dos a la vez: LlamaIndex gestiona la capa de datos y retrieval, LangChain orquesta el flujo de agente completo. No son competidores, son complementarios.
¿Cuándo usar LlamaIndex y cuándo no?
LlamaIndex tiene sentido cuando tu problema central es el acceso a datos privados o específicos del dominio. Concretamente:
Usa LlamaIndex si necesitas que un LLM responda preguntas sobre documentación interna de empresa (manuales, contratos, políticas, catálogos de producto). Si tienes datos en múltiples formatos y fuentes que necesitas unificar. Si el RAG de tu sistema está dando respuestas imprecisas o con hallucinations y necesitas más control sobre cómo se recupera el contexto.
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
No uses LlamaIndex —o no solo LlamaIndex— si tu problema es orquestar flujos de trabajo complejos entre múltiples agentes o herramientas externas. Para eso, LangChain o frameworks especializados en agentes como LangGraph o CrewAI son más apropiados.
Tampoco lo necesitas si tus "documentos" ya son cortos y autocontenidos —una FAQ donde cada entrada es una pregunta y su respuesta, fichas de producto cortas, tickets individuales—. En ese caso, cada registro ya es su propio chunk natural y la complejidad de LlamaIndex no aporta valor real.
¿Qué son LlamaHub y LlamaParse?
LlamaHub es el ecosistema de extensiones de código abierto para LlamaIndex. Contiene conectores de datos para más de cien fuentes (Notion, Google Drive, Slack, GitHub, bases de datos vectoriales, APIs de terceros), especificaciones de herramientas para agentes, y ejemplos de uso. Es el punto de entrada cuando necesitas conectar LlamaIndex a una fuente de datos que no viene incluida de serie.
LlamaParse es un producto comercial diferente. Es el parser de documentos de LlamaIndex AI —la empresa, no el framework— especializado en OCR agéntico: procesa PDFs complejos con tablas, gráficos e imágenes con alta precisión. No es de código abierto, aunque ofrece 10.000 créditos gratuitos al mes. La confusión entre LlamaIndex (el framework) y LlamaParse (el producto de pago) es frecuente: son dos cosas distintas que comparten el mismo origen.
¿Cómo se usa LlamaIndex para atención al cliente con IA?
El caso de uso más directo en empresa —y el que más hemos montado en GuruSup— es un agente de atención al cliente con IA que responde sobre la documentación propia de la empresa.
El patrón es siempre el mismo: cargas la documentación de producto, los procedimientos internos y las FAQs con los data connectors de LlamaIndex. Los indexas con VectorStoreIndex usando un modelo de embeddings en español o multilingüe. Conectas el query engine a un agente que gestiona la conversación. El agente recupera el contexto relevante para cada pregunta del cliente y el LLM genera la respuesta basándose en ese contexto, sin inventarse nada.
El resultado práctico: el agente responde sobre políticas de devolución, funcionamiento de productos o procedimientos de empresa con la misma precisión que tu mejor agente humano —y sin el riesgo de las hallucinations que tendría si le preguntaras al LLM sin contexto—. Es exactamente el tipo de sistema que alimenta una buena base de conocimiento con IA.
Lo que marca la diferencia en producción no es montar el pipeline base —eso es relativamente rápido con LlamaIndex—, sino ajustar el chunking, añadir búsqueda híbrida (vectorial + BM25 para términos exactos como nombres de producto o números de referencia, tal como explica nuestra guía sobre búsqueda semántica con IA), y medir con las métricas de evaluación nativas antes de desplegarlo.
Preguntas frecuentes sobre LlamaIndex
¿LlamaIndex es gratuito? El framework central es de código abierto y gratuito. LlamaParse, el parser de documentos complejos, es un producto comercial con un plan gratuito de 10.000 créditos al mes.
¿En qué lenguajes está disponible LlamaIndex? Principalmente en Python, que es donde está más maduro. Existe también una versión en TypeScript/JavaScript, aunque con menos integraciones disponibles.
¿LlamaIndex reemplaza a un vector database? No. LlamaIndex gestiona la lógica de indexing y retrieval, pero delega el almacenamiento en bases de datos vectoriales como Pinecone, Weaviate, Chroma o Qdrant. Por defecto almacena en memoria, lo que funciona para prototipos pero no escala a producción.
¿Se puede combinar LlamaIndex con modelos en español? Sí. LlamaIndex es agnóstico respecto al modelo de embeddings y al LLM. Puedes usar modelos de embeddings multilingües (como `paraphrase-multilingual-mpnet-base-v2`) y LLM con buen soporte para español. El chunking en documentos en español requiere prestar atención al tokenizador: algunos splitters ingenuos cortan mal con abreviaturas y puntuación española.
¿Cuándo apareció LlamaIndex? Se lanzó originalmente como "GPT Index" en 2022 y cambió su nombre a LlamaIndex en 2023. Desde entonces ha crecido hasta superar las 42.000 estrellas en GitHub.
¿LlamaIndex tiene agentes? Sí. Además de los query engines, LlamaIndex incluye soporte para data agents: sistemas que no solo recuperan información sino que pueden leer y escribir datos, hacer llamadas a APIs externas, mantener historial de conversación y ejecutar tareas complejas de múltiples pasos usando paradigmas de razonamiento como ReAct. Para casos donde el agente necesita actuar, no solo consultar, los data agents de LlamaIndex son el paso natural después de dominar el RAG básico.
---
Si estás evaluando qué stack montar para que tu equipo de atención al cliente deje de buscar respuestas a mano en documentación interna, el punto de partida es siempre el mismo: un pipeline RAG bien construido con LlamaIndex como capa de datos. En GuruSup montamos ese pipeline —conectores, indexing, búsqueda híbrida, evaluación— integrado directamente en los agentes de IA para empresas.