¿Qué son los embeddings en IA? Guía completa con modelos y casos de uso
Qué son los embeddings en IA, cómo convierten significado en números, espacio vectorial, distancia coseno, modelos (OpenAI, Cohere, open source) y cómo se usan en RAG y atención al cliente.
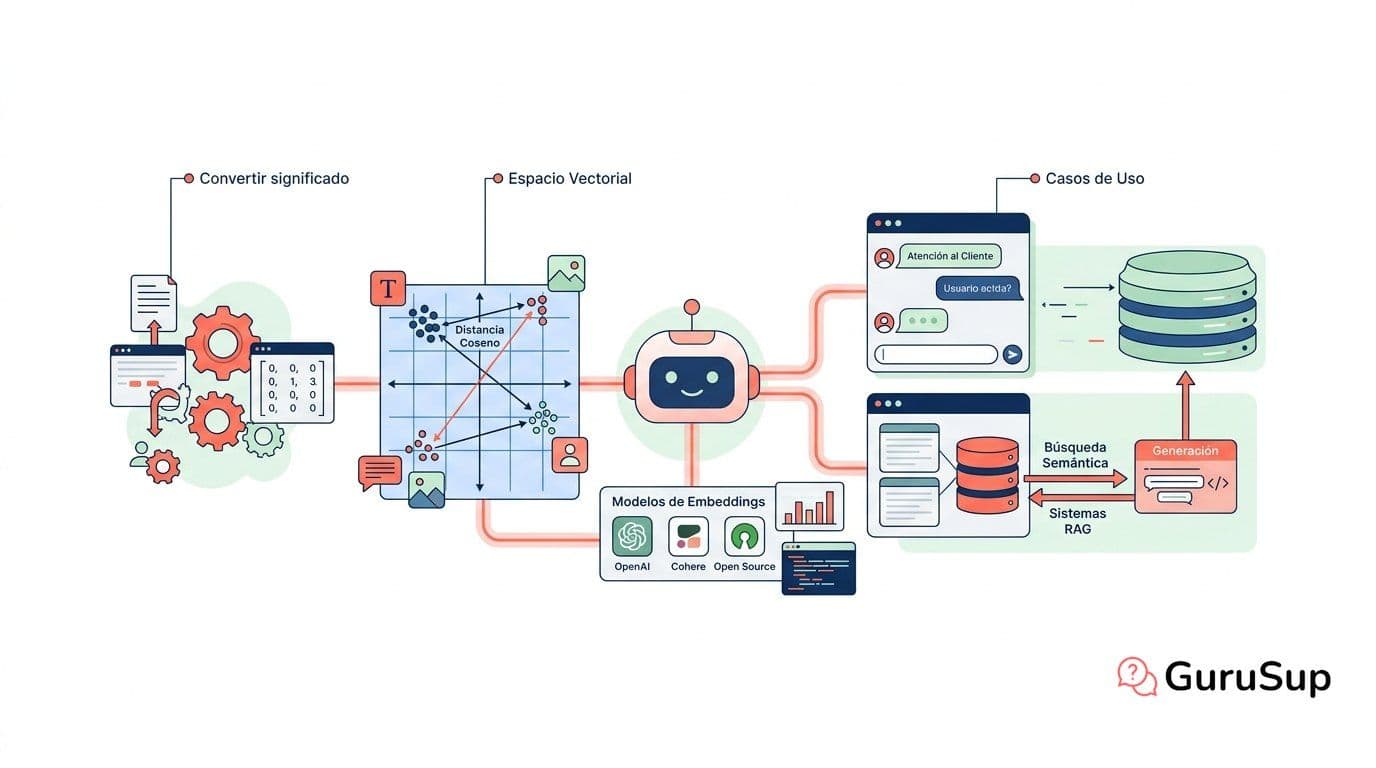
Tabla de contenidos
- ¿Por qué los embeddings "convierten significado en números"?
- ¿Qué es el espacio vectorial y cómo se organiza el significado?
- ¿Cómo aprende un modelo a generar embeddings?
- ¿Cómo se generan los embeddings?
- ¿Qué modelos de embeddings existen?
- ¿Para qué sirven los embeddings en la práctica?
- ¿Cómo usan los embeddings los agentes de IA en atención al cliente?
- Preguntas frecuentes sobre embeddings en IA
- Los embeddings no son una capa más
Llevas semanas montando tu primer agente de IA. Le conectas la documentación de tu empresa, haces la primera pregunta de prueba y el agente te devuelve algo que no viene a cuento. No es culpa del modelo de lenguaje. Tampoco del RAG en sí. Casi siempre, el origen del problema está antes: en los embeddings que transforman tus documentos en algo que la IA puede buscar.
En GuruSup llevamos tiempo montando agentes de IA que leen bases de conocimiento enteras para responder a clientes reales, y si algo aprendes pronto es que los embeddings no son un detalle técnico: son la capa que decide si tu agente entiende lo que le preguntan o se pierde en el primer sinónimo. Esta guía te explica qué son exactamente, por qué "convierten significado en números", cómo funciona el espacio vectorial donde viven, qué modelos puedes usar y cómo se aplican en atención al cliente y RAG empresarial.
¿Por qué los embeddings "convierten significado en números"?
La frase suena a magia, pero hay una razón muy concreta detrás. Un ordenador no puede comparar dos frases como lo haría un humano —no puede "sentir" que "política de devoluciones" y "cómo devolver un producto" dicen básicamente lo mismo—. Lo que sí puede hacer es comparar números.
Los embeddings son esa traducción. Toman una palabra, una frase o un párrafo entero y los convierten en un vector —una lista de números— que representa dónde cae ese texto en un espacio matemático de cientos o miles de dimensiones. Lo que consiguen es que textos con significado parecido acaben en posiciones cercanas de ese espacio, aunque usen palabras completamente distintas.
La clave es que esa proximidad no es arbitraria: el modelo aprendió, durante su entrenamiento con millones de textos, qué palabras y frases aparecen en contextos similares. "Devolver un pedido" y "política de devoluciones" coexisten en los mismos contextos en millones de documentos, así que el modelo los coloca cerca. "Devolver un pedido" y "la receta del gazpacho" nunca coexisten: acaban lejos.
Dicho de forma directa: los embeddings no traducen palabras a números de forma literal. Traducen el contexto en el que esas palabras existen. Por eso un embedding captura significado y no solo texto.
¿Qué es el espacio vectorial y cómo se organiza el significado?
Imagina una ciudad donde los barrios agrupan personas con intereses comunes. Los embeddings crean algo parecido: un espacio donde los textos viven en coordenadas, y los textos semanticamente parecidos son vecinos.
Ese espacio no tiene dos o tres dimensiones como un mapa. Tiene cientos o miles. Cada dimensión representa —de forma abstracta, no directamente interpretable— algún rasgo del texto: su campo semántico, su tono, su función gramatical, sus asociaciones contextuales. Ninguna dimensión tiene una etiqueta humana asignada; el modelo las aprende solo durante el entrenamiento.
Lo que sí puedes hacer con ese espacio vectorial es medir distancias. Y medir distancias es medir similitud semántica.
¿Cuántas dimensiones tiene un embedding?
Depende del modelo que uses. Algunos ejemplos concretos:
- OpenAI text-embedding-3-small — Dimensiones: 1.536 (reducible)
- OpenAI text-embedding-3-large — Dimensiones: 3.072
- Cohere Embed v3 — Dimensiones: 1.024
- BERT (base) — Dimensiones: 768
- all-MiniLM-L6-v2 (Sentence Transformers) — Dimensiones: 384
- BGE-M3 (open source multilingüe) — Dimensiones: 1.024
Más dimensiones no siempre significa mejor. Un vector más pequeño ocupa menos espacio en la base de datos vectorial, es más rápido de comparar y, con un buen modelo, puede rendir igual o mejor que uno enorme. La calidad viene del entrenamiento, no del tamaño.
¿Qué mide la distancia coseno (cosine similarity)?
La distancia coseno —o cosine similarity— es la métrica de similitud más usada con embeddings. No mide cuánto se parecen los vectores en tamaño absoluto, sino el ángulo entre ellos: si apuntan en la misma dirección, el texto es similar; si apuntan en direcciones opuestas, no tienen nada que ver.
El resultado va de -1 a 1. En la práctica:
- 0.9 - 1.0: textos casi idénticos en significado
- 0.7 - 0.9: textos relacionados, misma temática
- 0.5 - 0.7: conexión débil, contexto compartido
- < 0.5: textos sin relación semántica clara
Por qué coseno y no distancia euclidiana directa: porque el coseno ignora la magnitud del vector y solo mira la dirección. Eso funciona mejor con texto, donde un párrafo largo y uno corto pueden decir lo mismo aunque sus vectores tengan magnitudes muy distintas.
¿Cómo aprende un modelo a generar embeddings?
Antes de ver el proceso de uso, merece la pena entender cómo los modelos de embeddings aprenden esas representaciones. No se programan a mano: se aprenden desde datos.
El entrenamiento clásico —el que popularizó Word2Vec en 2013— funciona con una tarea de predicción: dado el contexto de una palabra, predice cuál es. O al revés: dada una palabra, predice su contexto. Para hacer esa predicción bien, la red neuronal tiene que aprender representaciones que capturen el significado. Los vectores que emergen de ese entrenamiento son los embeddings.
Los modelos modernos —BERT, los encoders basados en transformer— van más lejos. Se entrenan en tareas como predecir fragmentos enmascarados del texto o clasificar si dos frases son consecutivas. Lo que aprenden en ese proceso es una representación contextual: el mismo token "banco" tiene un embedding distinto cuando aparece en "fui al banco a sacar dinero" y cuando aparece en "me senté en el banco del parque". Eso es lo que los hace mucho más útiles para retrieval que los modelos clásicos de palabra aislada.
Los modelos especializados en embeddings para búsqueda —como los de OpenAI, Cohere o Sentence Transformers— añaden una fase de entrenamiento adicional: aprenden a maximizar la similitud entre queries y documentos relevantes, y a minimizarla entre queries y documentos irrelevantes. Eso los hace especialmente buenos para el caso de uso que más nos importa: encontrar el fragmento correcto cuando un usuario hace una pregunta.
¿Cómo se generan los embeddings?
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
El proceso es mecánico una vez que tienes el modelo elegido:
- Tomas el texto —una frase, un párrafo, un chunk de un documento.
- Lo pasas por el modelo de embeddings, que lo tokeniza y lo procesa a través de sus capas.
- El modelo devuelve un vector —esa lista de números de 384, 768 o 1.536 dimensiones.
- Guardas ese vector en una base de datos vectorial junto con el texto original y los metadatos relevantes.
Cada vez que un usuario hace una pregunta, haces exactamente lo mismo: conviertes la pregunta en un embedding y buscas los vectores más cercanos en la base de datos. Esos vectores corresponden a los fragmentos de texto más similares semánticamente. Ahí está el retrieval.
Hay un detalle que muchos tutoriales omiten: el modelo de embeddings que usas para indexar y el que usas para buscar deben ser el mismo. Si indexas con OpenAI y buscas con Cohere, los vectores viven en espacios distintos y la comparación no tiene sentido. El espacio vectorial es propiedad del modelo que lo genera.
El segundo detalle que tampoco se menciona casi nunca: cada modelo de embeddings tiene su propio context window, es decir, un límite de tokens que puede procesar de una vez. Si le mandas un chunk que supera ese límite, el modelo lo trunca silenciosamente —sin error, sin aviso— y el embedding resultante solo representa la parte del texto que llegó a procesar. El resto desaparece.
Algunos límites de referencia:
- OpenAI text-embedding-3-small / large — Context window (tokens): 8.191
- Cohere Embed v3 — Context window (tokens): 512
- all-MiniLM-L6-v2 — Context window (tokens): 256
- BGE-M3 — Context window (tokens): 8.192
- multilingual-e5-large — Context window (tokens): 512
La consecuencia práctica: si usas `all-MiniLM-L6-v2` o `multilingual-e5-large` y mandas chunks de 1.000 tokens, la mitad de cada chunk se pierde. Tu estrategia de chunking y tu modelo de embeddings tienen que estar coordinados. El tamaño del chunk no solo depende de la semántica del documento —también depende del modelo que vas a usar para indexarlo.
¿Qué modelos de embeddings existen?
Aquí es donde la mayoría de las guías en español se quedan cortas. Hay opciones muy distintas según tu caso: propietarias, open source, especializadas en código o multilingüismo. Vamos por partes.
OpenAI Embeddings
Los modelos de OpenAI —`text-embedding-3-small` y `text-embedding-3-large`— son los más usados por defecto en proyectos que ya trabajan con GPT-4 o GPT-4o. Sus ventajas son la facilidad de integración vía API, la buena calidad general y la posibilidad de reducir dimensiones sin coste de calidad grave (algo que OpenAI llama *Matryoshka Representation Learning*).
Su inconveniente es el coste por token cuando procesas volúmenes altos, y la dependencia de un proveedor externo: cada vez que quieres generar o comparar embeddings, haces una llamada a su API.
Cohere Embed
Cohere Embed v3 es una alternativa seria a OpenAI, especialmente en casos donde el retrieval de documentos largos importa. Tienen un parámetro `input_type` que distingue si estás codificando una query o un documento, lo que mejora la precisión del retrieval porque el modelo sabe qué rol juega cada texto. Es un detalle pequeño que marca diferencia en producción.
Modelos open source (Sentence Transformers, BGE, E5)
Si no quieres depender de APIs externas o procesas volúmenes donde el coste por llamada importa, los modelos open source son una opción real y madura:
- all-MiniLM-L6-v2: 384 dimensiones, rápido, eficiente. Buen punto de partida para proyectos en inglés con recursos limitados.
- BGE-M3 (BAAI): multilingüe, 1.024 dimensiones, uno de los mejores modelos open source disponibles actualmente. Soporta más de 100 idiomas incluyendo español.
- E5-large-v2 (Microsoft): muy competitivo en benchmarks de retrieval en inglés.
- multilingual-e5-large: variante multilingüe del E5, buena opción para proyectos en español que necesitan embeddings de calidad sin coste de API.
Todos estos modelos se ejecutan localmente con la librería `sentence-transformers` de Hugging Face, lo que significa cero coste por inferencia una vez descargado el modelo.
¿Qué pasa con los embeddings multilingües?
Este punto importa especialmente si tu empresa opera en español —o en varios idiomas—. Los modelos monolingües en inglés generan embeddings de mala calidad para texto en español: las relaciones semánticas que aprendieron con corpus ingleses no se transfieren bien.
Un modelo como BGE-M3 o multilingual-e5-large entiende que "política de devoluciones" y "return policy" están diciendo lo mismo. Eso permite hacer búsquedas semánticas cruzadas entre idiomas y construir bases de conocimiento que sirvan a equipos o clientes en varios mercados sin duplicar la indexación.
Para empresas españolas con documentación en castellano: usar un modelo monolingüe en inglés es uno de los errores más frecuentes y más costosos en términos de calidad de retrieval.
¿Para qué sirven los embeddings en la práctica?
El espacio teórico está bien, pero lo que te interesa saber es qué problemas reales resuelven.
Búsqueda semántica
La búsqueda tradicional funciona por coincidencia de palabras: si buscas "devolver pedido", solo encuentras documentos que contienen exactamente esas palabras. La búsqueda semántica con IA basada en embeddings encuentra documentos que hablan del mismo tema aunque usen vocabulario distinto.
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Eso significa que si un cliente escribe "quiero cancelar mi compra", el sistema encuentra la sección de "política de devoluciones" aunque no haya ni una sola palabra en común. El match es por significado, no por texto literal.
En una base de conocimiento con IA, esto marca la diferencia entre un agente que siempre encuentra la respuesta correcta y uno que falla cuando el cliente no usa exactamente las palabras del manual.
RAG (Retrieval-Augmented Generation)
Los embeddings son el motor del retrieval en un sistema RAG. El pipeline es este:
- Partes los documentos en chunks (con la estrategia de chunking que elijas —fixed-size, recursive, semántico—).
- Generas un embedding por chunk y los guardas en la base de datos vectorial.
- Cuando llega una pregunta, la conviertes en embedding y buscas los chunks más cercanos.
- Esos chunks se pasan al LLM como contexto para que genere la respuesta.
La calidad del retrieval —y por tanto de la respuesta final— depende directamente de la calidad de los embeddings. Un mal modelo de embeddings recupera chunks irrelevantes, y el LLM tiene que improvisar con contexto equivocado. Ahí es donde aparecen las alucinaciones.
Sistemas de recomendación y clasificación
Fuera del RAG, los embeddings tienen aplicaciones igual de potentes:
- Clasificación de tickets: conviertes cada ticket de soporte en un embedding y lo comparas con categorías predefinidas para enrutarlo automáticamente al equipo correcto.
- Detección de duplicados: comparas embeddings de tickets nuevos con los históricos para detectar que un cliente está enviando el mismo problema por segunda vez.
- Análisis de sentimiento semántico: en lugar de reglas léxicas, usas la posición del embedding en el espacio para inferir el tono.
- Recomendación de contenido: si sabes qué documentación leyó un usuario, buscas embeddings cercanos para sugerir contenido relacionado.
¿Cómo usan los embeddings los agentes de IA en atención al cliente?
Este es el caso de uso donde los embeddings pasan de ser un concepto técnico a tener impacto directo en el negocio.
Cuando un cliente escribe "no me llegó el paquete" a las 11 de la noche, un agente de IA bien construido no intenta hacer pattern matching con esa frase. Lo que hace es:
- Convierte la pregunta en un embedding usando el mismo modelo con el que indexó la base de conocimiento.
- Busca los chunks más similares en la base de datos vectorial —la sección de incidencias de envío, la política de compensaciones, el procedimiento de apertura de caso—.
- Pasa esos chunks al LLM junto con la pregunta del cliente.
- El LLM genera una respuesta fundamentada en la documentación real de la empresa, no inventada.
El resultado es un agente que responde con la información correcta de tu empresa, actualizada, sin improvisar y sin que el cliente note que no hay un humano al otro lado.
Lo que hace posible todo eso —que el agente encuentre "incidencias de envío" cuando el cliente dice "no me llegó el paquete"— son los embeddings. Sin ellos, el sistema no sabe que esas dos frases hablan del mismo problema.
El segundo beneficio que vemos en producción es la escalabilidad sin pérdida de calidad: el mismo agente que responde un ticket de envíos puede responder sobre facturación, garantías o configuración de producto, porque el retrieval por embeddings busca en toda la base de conocimiento, no en listas de intenciones predefinidas.
Preguntas frecuentes sobre embeddings en IA
¿Los embeddings son lo mismo que los vectores? No exactamente. Un vector es la estructura matemática —la lista de números—. Un embedding es un vector que representa el significado de algo: un texto, una imagen, un audio. Todo embedding es un vector, pero no todo vector es un embedding.
¿ChatGPT usa embeddings? Sí, aunque de forma interna. Los modelos GPT usan capas de embeddings para procesar el texto que reciben antes de generar respuestas. Cuando usas la API de OpenAI Embeddings, estás usando un modelo distinto, optimizado específicamente para generar vectores que sirvan para búsqueda y retrieval, no para generar texto.
¿Puedo usar embeddings con texto en español? Sí, pero elige bien el modelo. Los modelos monolingües en inglés rinden mal con texto en castellano. Usa modelos multilingües como BGE-M3, multilingual-e5-large o los modelos de OpenAI y Cohere, que tienen buen soporte para español.
¿Cuánto cuesta generar embeddings? Depende de la estrategia. Con modelos de OpenAI o Cohere pagas por tokens procesados. Con modelos open source ejecutados localmente, el coste es el cómputo de tu infraestructura. Para la mayoría de proyectos de empresa —bases de conocimiento de tamaño razonable—, la diferencia económica real viene del volumen de actualizaciones, no de la indexación inicial.
¿Los embeddings quedan obsoletos? Los embeddings que generas hoy son válidos mientras no cambies el modelo. Si migras a un modelo distinto —porque salió una versión mejor o cambias de proveedor—, tienes que re-indexar todos tus documentos. No es trivial en bases de conocimiento grandes, así que es una decisión de arquitectura que conviene tomar desde el principio.
¿Embeddings o fine-tuning? Resuelven problemas distintos. Los embeddings dentro de RAG sirven para que el modelo responda con información actualizada de tu empresa sin reentrenarlo. El fine-tuning cambia el comportamiento o el tono del modelo. En la mayoría de casos de empresa, empiezas por RAG con buenos embeddings y solo planteas fine-tuning cuando los datos de comportamiento lo justifican.
Los embeddings no son una capa más
Cuando ves un sistema de RAG que responde mal, busca primero en los embeddings: qué modelo estás usando, si es el adecuado para tu idioma, si el chunk size está alineado con el context window del modelo, si estás usando la misma versión para indexar y para buscar. Ahí está casi siempre el origen del problema.
Los embeddings son la capa de traducción entre el lenguaje humano y la búsqueda semántica. Acertar con el modelo y la configuración no resuelve todos los problemas de un RAG, pero un modelo equivocado los crea todos.
En GuruSup montamos el pipeline completo —embeddings, retrieval, reranking y evaluación— para los agentes que atienden a clientes sobre la documentación de cada empresa. Si tu agente recupera mal o da respuestas que no vienen a cuento, mira nuestro software de base de conocimiento con IA.