¿Qué es una base de datos vectorial? Guía técnica y práctica
Qué es una base de datos vectorial, cómo funciona por dentro (HNSW, IVF, ANN, cosine similarity) y cuál elegir entre Pinecone, Qdrant, Chroma, Milvus, Weaviate y pgvector según tu caso.
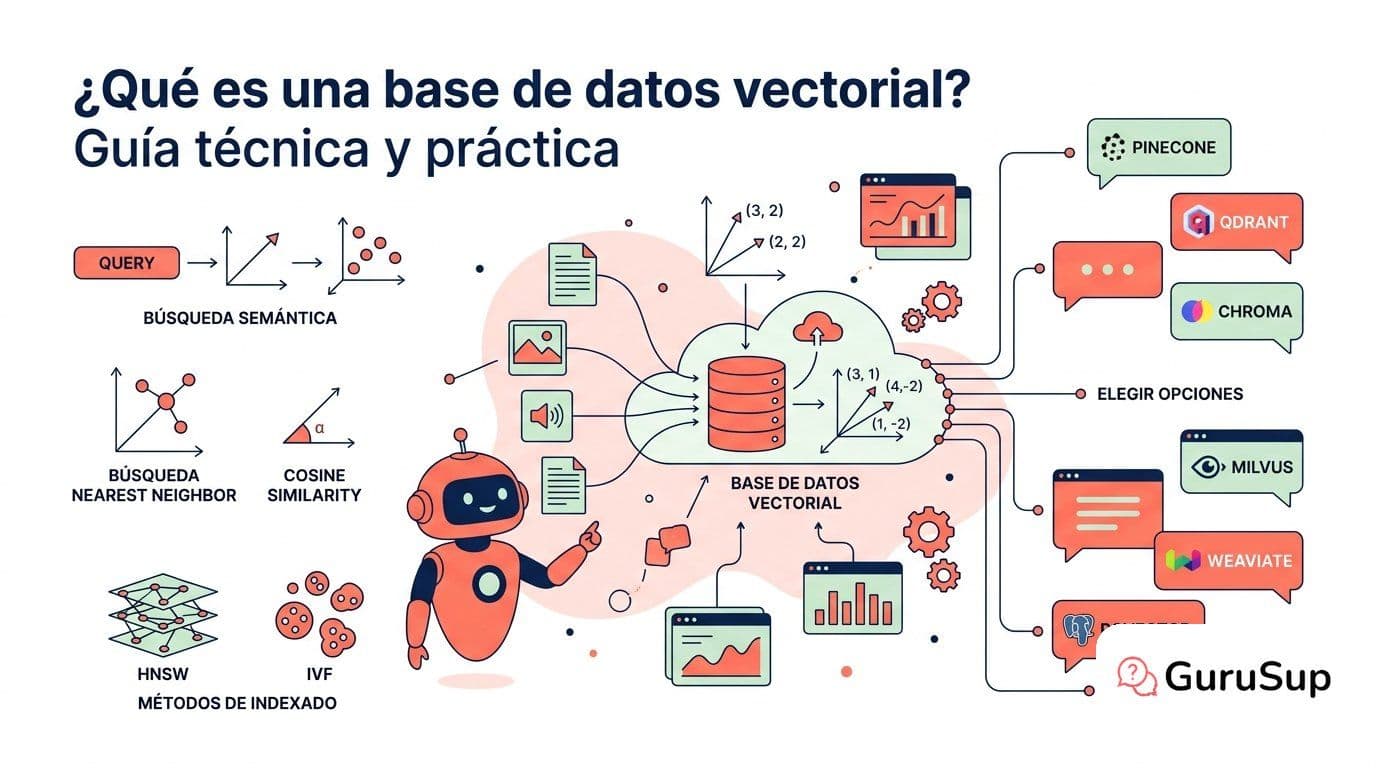
Tabla de contenidos
- ¿Por qué SQL no sirve para buscar por significado?
- ¿Qué son los embeddings y qué relación tienen con una base de datos vectorial?
- ¿Cómo funciona una base de datos vectorial por dentro?
- ¿Qué casos de uso tiene una base de datos vectorial?
- ¿Cuál elegir? Pinecone, Qdrant, Chroma, Milvus, Weaviate y pgvector comparados
- ¿Cuándo NO necesitas una base de datos vectorial dedicada?
- Base de datos vectorial en RAG: cómo encajan las piezas
- Preguntas frecuentes sobre bases de datos vectoriales
Llevas semanas leyendo sobre RAG, agentes de IA y LLMs. En algún momento aparece el mismo término: base de datos vectorial. A veces también lo verás en inglés, como *vector database*. Y casi siempre aparece con la misma explicación de tres líneas que te deja exactamente igual que estabas.
En GuruSup llevamos tiempo construyendo agentes de IA que buscan respuestas en bases de conocimiento reales — manuales de producto, políticas de empresa, catálogos — para responder a clientes sin que un humano tenga que estar detrás. En ese proceso, la base de datos vectorial es la pieza que hace posible que el agente encuentre lo relevante entre miles de documentos en milisegundos. No es un detalle de infraestructura: es el motor de búsqueda.
Esta guía no es un tour de marketing de las distintas herramientas. Es una explicación técnica y práctica de qué es una base de datos vectorial, cómo funciona por dentro, qué diferencia a cada opción del mercado y, sobre todo, cuándo necesitas una de verdad y cuándo no.
¿Por qué SQL no sirve para buscar por significado?
Antes de explicar qué es una base de datos vectorial, hace falta entender el problema que resuelve. Porque no es un capricho tecnológico: es la única forma que existe de hacer un tipo concreto de búsqueda.
Una base de datos relacional —MySQL, PostgreSQL, cualquier cosa que hables con SQL— está diseñada para responder preguntas exactas. ¿Tiene este usuario el campo `plan = "premium"`? ¿Qué pedidos tienen `estado = "enviado"`? Son preguntas de coincidencia: o el valor está o no está. SQL busca por igualdad, por rango, por patrones de texto (`LIKE`). Lo que no puede hacer SQL es decirte qué fila es "más parecida" a otra en términos de significado.
Imagina que tienes mil artículos de soporte y un cliente escribe: "mi factura no llega". Tu base de datos relacional busca esas palabras exactas. Si el artículo correcto se llama "problemas con la recepción de facturas por email", no lo encuentra. Para SQL, "factura no llega" y "recepción de facturas" no tienen relación porque no comparten las mismas palabras.
- Búsqueda exacta (SQL, LIKE) — Qué hace: Encuentra coincidencias léxicas · Ejemplo: "factura" → solo resultados con la palabra "factura"
- Búsqueda vectorial — Qué hace: Encuentra similitud semántica · Ejemplo: "factura no llega" → "recepción de facturas por email"
- Búsqueda híbrida (vectorial + BM25) — Qué hace: Ambas a la vez · Ejemplo: Nombres propios + conceptos relacionados
La búsqueda vectorial no compara palabras: compara significados. Y para comparar significados, necesita una representación matemática de esos significados. Ahí entran los embeddings.
¿Qué son los embeddings y qué relación tienen con una base de datos vectorial?
Un embedding es un vector numérico que representa el significado de un texto (o una imagen, o un audio). Lo genera un modelo de machine learning entrenado para capturar relaciones semánticas. El resultado es una lista de números —400, 768, 1536 dimensiones dependiendo del modelo— donde textos con significados parecidos producen vectores parecidos: es decir, vectores que están cerca en ese espacio de alta dimensión.
"Factura no llega" y "recepción de facturas por email" producen vectores que están cerca el uno del otro. "Factura no llega" y "política de devoluciones de zapatos" producen vectores alejados. El modelo ya aprendió esas relaciones durante el entrenamiento.
La base de datos vectorial almacena esos vectores. Cuando llega una consulta, la convierte también en un embedding y busca los vectores almacenados que están más cerca. Eso es todo. Lo que cambia de una herramienta a otra es cómo organiza los vectores para que esa búsqueda sea rápida con millones de entradas. Esa organización es el índice vectorial, y es donde reside la diferencia real entre herramientas.
Si quieres entender en profundidad cómo se generan y entrenan los embeddings, puedes leer qué son los embeddings en IA. En esta guía partimos desde el punto en que ya los tienes y necesitas guardarlos.
¿Cómo funciona una base de datos vectorial por dentro?
Aquí está la parte que la mayoría de artículos evita: el mecanismo real. No hace falta matemática avanzada para entenderlo; sí hace falta saber qué ocurre para tomar buenas decisiones de arquitectura.
¿Qué es el ANN (Approximate Nearest Neighbor)?
La búsqueda exacta del vector más cercano —el problema del *k-Nearest Neighbor* o kNN— requiere comparar la consulta contra todos los vectores almacenados. Con 1.000 documentos, perfecto. Con 10 millones, imposible a tiempo real.
La solución es ANN: Approximate Nearest Neighbor. En lugar de garantizar que encuentras el vecino más cercano de forma exacta, ANN garantiza que encuentras un vecino muy cercano (con un error controlado y configurable) en un tiempo radicalmente menor. Para búsqueda semántica, ese pequeño compromiso de precisión es completamente aceptable: si el resultado es 99% relevante en lugar del 100% exacto, al usuario le da igual.
Todos los índices vectoriales modernos son variantes de ANN. La pregunta es qué estructura de datos usan para organizar los vectores antes de buscar.
¿Qué es HNSW y por qué es el índice más usado?
HNSW (Hierarchical Navigable Small World) es el algoritmo de indexación que usan Qdrant, Weaviate y la mayoría de bases de datos vectoriales modernas como opción por defecto. Su funcionamiento se puede entender con una analogía:
Imagina que tienes que encontrar a una persona en una ciudad desconocida. Una estrategia eficaz sería: primero orientarte a nivel de país (¿norte o sur?), luego a nivel de ciudad, luego de barrio, luego de calle, luego de número. En lugar de buscar casa por casa desde el principio, navegas desde lo general hasta lo específico.
HNSW hace exactamente eso con vectores. Construye un grafo de capas: la capa superior conecta pocos nodos muy representativos (los "hubs" del espacio vectorial); cada capa inferior es más densa y más local. Al buscar, el algoritmo empieza en la capa superior, baja de capa en capa refinando, y llega a los candidatos finales sin recorrer todo el espacio.
El resultado práctico: búsquedas de vectores en colecciones de millones de entradas en 1-10 milisegundos. La contrapartida es que HNSW consume bastante memoria RAM porque el grafo debe estar en memoria. En colecciones muy grandes (cientos de millones de vectores), puede ser prohibitivo.
Parámetros clave de HNSW que aparecerán en tu configuración:
- `ef_construction`: cuántos candidatos explora al construir el índice. Más alto = índice de mayor calidad, construcción más lenta.
- `ef` (o `ef_search`): cuántos candidatos explora en cada búsqueda. Más alto = más preciso, más lento.
- `M`: número de conexiones por nodo en el grafo. Más alto = mejor recall, más memoria.
¿Qué es IVF (Inverted File Index) y cuándo conviene?
IVF (Inverted File Index) es otro algoritmo de ANN, diferente a HNSW. La idea: dividir el espacio vectorial en *clusters* (mediante k-means u otro método de agrupación), y al buscar, solo explorar los clusters más cercanos a la consulta en lugar de todo el espacio.
IVF consume menos memoria que HNSW porque no necesita mantener el grafo entero en RAM: puede trabajar con los vectores en disco y cargar solo los clusters relevantes. Es la opción natural para colecciones masivas (decenas o cientos de millones de vectores) donde la memoria es el cuello de botella.
Convierte la atención al cliente en fidelización y recomendaciones con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Milvus y Faiss (la librería de Meta que hay debajo de muchas implementaciones) son los que mejor soportan IVF con sus variantes: `IVF_FLAT`, `IVF_SQ8` (con cuantización escalar), `IVF_PQ` (con cuantización por producto). Cada variante es un compromiso distinto entre velocidad, memoria y precisión.
¿HNSW o IVF? Para la mayoría de proyectos con colecciones de hasta unos pocos millones de vectores, HNSW. Para colecciones que crecen sin límite o donde la memoria RAM es el recurso más escaso, IVF o sus variantes cuantizadas.
¿Cosine similarity y dot product: ¿cuál mide qué?
Una vez que el índice ha identificado los candidatos, necesitas una métrica de distancia para ordenarlos. Las dos más habituales son:
Cosine similarity (similitud de coseno): mide el ángulo entre dos vectores, independientemente de su magnitud. Si dos vectores apuntan en la misma dirección, cosine similarity = 1 (idénticos); si apuntan en direcciones opuestas, = -1. La magnitud (la "longitud" del vector) no influye. Es la métrica por defecto para embeddings de texto, porque lo que importa es la dirección semántica, no la intensidad.
Dot product (producto escalar): multiplica las componentes de los dos vectores y suma los resultados. A diferencia del coseno, sí depende de la magnitud. Con vectores normalizados (longitud = 1), dot product y cosine similarity son equivalentes. Sin normalizar, el dot product favorece vectores más "largos", lo que puede ser útil en algunos modelos de recomendación donde la magnitud tiene significado.
Distancia euclidiana: la distancia en línea recta entre dos puntos en el espacio multidimensional. Intuitiva, pero generalmente peor que cosine similarity para búsqueda semántica porque mezcla dirección y magnitud de formas no deseadas.
La regla práctica para el 95% de los casos: usa cosine similarity salvo que el proveedor del modelo de embeddings indique expresamente otra cosa.
¿Qué casos de uso tiene una base de datos vectorial?
La base de datos vectorial no es una solución universal: es la herramienta correcta para un conjunto concreto de problemas. Estos son los principales:
Búsqueda semántica en documentos. El caso de uso fundacional. En lugar de buscar por palabras clave, el usuario hace una pregunta en lenguaje natural y el sistema recupera los fragmentos más relevantes, aunque usen vocabulario diferente. Aplicaciones: buscadores internos, motores de búsqueda de documentación técnica, catálogos de productos, bases de conocimiento internas. La diferencia respecto a un buscador clásico es que el usuario puede preguntar "¿cómo activo la renovación automática?" y el sistema recupera el artículo titulado "Gestión de suscripciones y ciclos de facturación" sin que ambos textos compartan ni una palabra.
RAG (Retrieval-Augmented Generation). El agente de IA necesita responder con información que no estaba en su entrenamiento. La base de datos vectorial actúa como la memoria externa del agente: el agente busca en ella antes de responder, de modo que la respuesta se basa en tu documentación real y no en lo que el modelo "recuerda" de su entrenamiento. Esto resuelve el problema de la información desactualizada o privada: el modelo no sabe nada de tu empresa, pero la base de datos vectorial sí. Para profundizar en cómo se ensambla este pipeline, puedes leer qué es RAG.
Recomendación. Conviertes cada producto, artículo o contenido en un embedding y buscas los más cercanos al ítem que el usuario acaba de ver o comprar. El resultado es una recomendación por similitud de características semánticas, sin que nadie haya tenido que etiquetar manualmente las relaciones. Funciona especialmente bien con catálogos grandes y heterogéneos donde las reglas manuales de recomendación son imposibles de mantener.
Detección de duplicados y deduplicación. Dos textos que dicen lo mismo con palabras distintas tendrán embeddings cercanos. Puedes detectar automáticamente contenido duplicado, preguntas repetidas en un ticket de soporte, o registros parecidos en una base de datos. Un equipo de soporte con miles de tickets mensuales puede usar esto para agrupar automáticamente incidencias similares y escalarlas juntas.
Atención al cliente con agentes de IA. Un agente que atiende a clientes necesita encontrar, en milisegundos y entre miles de artículos de soporte, la respuesta correcta a la pregunta del cliente. La base de datos vectorial hace esa búsqueda semántica en tiempo real; el LLM transforma el resultado en una respuesta coherente y adaptada al tono de la conversación. El software de base de conocimiento con IA es la capa que une estas piezas en un sistema que cualquier equipo de soporte puede operar sin saber nada de vectores. La diferencia práctica: un agente con buena base de datos vectorial contesta "¿puedo cambiar mi plan a mitad de mes?" correctamente aunque el artículo de soporte hable de "modificación de suscripción en período activo".
Clustering y análisis de texto a escala. Agrupar miles de tickets de soporte por tema, encontrar patrones en respuestas de encuestas abiertas, segmentar usuarios por comportamiento descrito en texto libre. La base de datos vectorial convierte texto en una estructura matemática que puedes analizar con algoritmos de clustering estándar — k-means, DBSCAN — sin necesidad de etiquetar los datos manualmente.
Detección de anomalías y seguridad. Un documento o transacción semánticamente muy diferente del resto del corpus puede indicar un problema: un email de phishing que "suena" diferente al historial de comunicaciones, una instrucción de pago con vocabulario inusual. Los sistemas de detección de fraude cada vez integran más búsqueda vectorial para este tipo de análisis.
¿Cuál elegir? Pinecone, Qdrant, Chroma, Milvus, Weaviate y pgvector comparados
Aquí está el análisis real, sin el barniz de "todas son excelentes":
- **Pinecone** — Tipo: Managed (cloud) · Índice por defecto: HNSW · Filtrado de metadatos: Sí (robusto) · Escalabilidad: Muy alta · Cuándo usarla: Producción sin ops. No quieres tocar infraestructura.
- **Qdrant** — Tipo: Open source / managed · Índice por defecto: HNSW · Filtrado de metadatos: Sí (muy potente) · Escalabilidad: Alta · Cuándo usarla: Producción on-premise o cloud. Mejor open source del mercado hoy.
- **Chroma** — Tipo: Open source · Índice por defecto: HNSW (local) · Filtrado de metadatos: Sí (básico) · Escalabilidad: Baja · Cuándo usarla: Desarrollo local y prototipos. No escala a producción sin trabajo extra.
- **Milvus** — Tipo: Open source / managed · Índice por defecto: HNSW + IVF · Filtrado de metadatos: Sí · Escalabilidad: Muy alta · Cuándo usarla: Colecciones masivas. Empresas con equipos de datos propios.
- **Weaviate** — Tipo: Open source / managed · Índice por defecto: HNSW · Filtrado de metadatos: Sí + esquema GraphQL · Escalabilidad: Alta · Cuándo usarla: Cuando necesitas GraphQL o búsqueda multimodal (texto + imagen).
- **pgvector** — Tipo: Extensión PostgreSQL · Índice por defecto: HNSW + IVF · Filtrado de metadatos: Sí (SQL completo) · Escalabilidad: Media · Cuándo usarla: Ya tienes Postgres. Colecciones de hasta ~1M vectores. Sin ops extra.
Pinecone es la opción managed por excelencia: sin servers que gestionar, SLA claro, escala sin esfuerzo. El precio sube con el volumen y estás en su cloud. Si tu equipo no tiene capacidad de ops y necesitas algo en producción rápido, es una opción sólida.
Qdrant es la opción open source más madura en este momento. Su HNSW es rápido, el filtrado de metadatos es de los más potentes del mercado (puedes combinar filtros complejos con la búsqueda vectorial sin degradar el rendimiento), y tiene versión cloud gestionada si no quieres operar la infraestructura. Para la mayoría de proyectos de producción con un equipo técnico, Qdrant es la elección más equilibrada hoy.
Chroma brilla en desarrollo local y prototipos. Se instala con un `pip install` y funciona en memoria o en disco sin configuración. Para producción con volumen real, no está pensada para eso y lo empieza a notar.
Milvus está diseñado para escala masiva: cientos de millones de vectores, cargas de escritura intensas, arquitectura distribuida. Si no tienes ese problema todavía, añade complejidad operacional innecesaria.
Weaviate tiene un modelo de datos más rico (esquema de objetos, propiedades, relaciones) y soporta búsqueda multimodal nativamente. Su API GraphQL es potente pero tiene una curva de aprendizaje mayor. Buena opción cuando el caso de uso va más allá de la búsqueda semántica pura.
pgvector es la extensión vectorial para PostgreSQL. Si ya tienes Postgres en producción y tu colección no supera el millón de vectores, añadir pgvector es la solución con menor fricción posible: los vectores viven junto al resto de tus datos, puedes hacer JOINs entre vectores y registros relacionales, y operas una sola base de datos. Por encima del millón de vectores, el rendimiento de HNSW en pgvector empieza a mostrar sus límites frente a las opciones nativas.
¿Cuándo NO necesitas una base de datos vectorial dedicada?
Esta es la pregunta que casi nadie responde: ¿cuándo te sobra con lo que tienes?
Si tu colección es pequeña. Con menos de 10.000-50.000 vectores, la búsqueda exacta kNN sobre un array en memoria (NumPy, Faiss en memoria) es perfectamente viable y elimina toda la complejidad operacional. No necesitas levantar ningún servicio adicional.
Si ya tienes PostgreSQL y la escala es moderada. pgvector con HNSW resuelve la búsqueda vectorial dentro de tu Postgres existente. Para colecciones de hasta unos cientos de miles de vectores con una carga de consultas normal, pgvector funciona bien y te evita operar otro sistema.
Si tu búsqueda es ante todo léxica con un toque semántico. Elasticsearch y OpenSearch tienen búsqueda vectorial integrada. Si ya los usas y la búsqueda híbrida (BM25 + vectorial) te da resultados suficientemente buenos, no necesitas añadir una base de datos vectorial separada.
Una mejor atención al cliente empieza con GuruSup
Soporte con IA que escala sin perder cercanía. Demo de 20 min.
Si tus "documentos" ya son cortos y muy estructurados. Una FAQ con 200 entradas, fichas de producto con campos definidos, tickets individuales: cada registro ya es su propio chunk natural. Una búsqueda semántica ligera sobre un conjunto pequeño no necesita la artillería de Pinecone o Qdrant.
La base de datos vectorial dedicada tiene sentido cuando: la colección es grande y crece, la búsqueda por similitud es el core de tu producto, necesitas filtrado de metadatos complejo combinado con búsqueda vectorial, o la latencia importa mucho a escala.
Base de datos vectorial en RAG: cómo encajan las piezas
Si ya has leído sobre RAG, sabes que el flujo básico es: documento → chunks → embeddings → almacenamiento → retrieval → generación. La base de datos vectorial vive en el medio de ese flujo.
El punto clave que muchos tutoriales no dejan claro: la calidad de la base de datos vectorial no rescata un chunking malo. Si los fragmentos que indexaste mezclan varios temas, si cortaste en mitad de una frase importante, si los chunks son tan pequeños que perdieron contexto — ningún índice HNSW va a recuperar algo útil. El chunking decide la calidad de lo que entra; la base de datos vectorial decide la eficiencia con la que se busca.
Las piezas que interactúan directamente con la base de datos vectorial:
El chunking. Define el tamaño y la coherencia de lo que indexas. Un chunk bien formado produce un embedding que representa claramente un concepto. Un chunk caótico produce un embedding que representa nada. Si quieres entender las estrategias de chunking en detalle, la guía de chunking en RAG cubre desde fixed-size hasta agentic chunking.
El modelo de embeddings. Elige el modelo antes de decidir la configuración de la base de datos vectorial: el número de dimensiones del vector tiene que coincidir, y algunos modelos producen mejores embeddings para dominios específicos (código, texto médico, inglés técnico).
El filtrado de metadatos. Una base de datos vectorial no es solo un índice de vectores: es también un almacén de metadatos asociados (categoría, fecha, autor, idioma, tipo de documento). El filtrado de metadatos permite combinar búsqueda semántica con restricciones precisas: "encuentra los fragmentos más relevantes sobre devoluciones, pero solo de artículos publicados después de enero y en español". En atención al cliente esto es crítico: un agente que atiende a clientes de diferentes países o planes no puede mezclar políticas.
La búsqueda híbrida. La búsqueda puramente vectorial falla con términos muy específicos: números de pedido, códigos de producto, nombres propios. Al combinar la búsqueda vectorial con BM25 (búsqueda léxica clásica), el sistema captura tanto la similitud semántica como la coincidencia exacta — lo que se conoce como búsqueda semántica con IA. Pinecone, Qdrant y Weaviate soportan búsqueda híbrida de forma nativa; con pgvector se puede implementar manualmente.
Preguntas frecuentes sobre bases de datos vectoriales
¿Una base de datos vectorial reemplaza a mi base de datos relacional?
No. Son complementarias, no alternativas. Tu base de datos relacional sigue gestionando transacciones, registros de usuarios, pedidos, configuraciones. La base de datos vectorial gestiona la búsqueda semántica sobre contenido no estructurado. La mayoría de arquitecturas las usan en paralelo: la consulta busca en la VDB para encontrar contexto y en la relacional para recuperar datos de negocio.
¿Cuántas dimensiones necesito en mis vectores?
Depende del modelo de embeddings que elijas, no de tu decisión. Los modelos más ligeros generan vectores de 384 o 768 dimensiones; los más potentes llegan a 1536 o más. Más dimensiones implica embeddings más ricos pero más memoria y más tiempo de búsqueda. Para la mayoría de aplicaciones en español, modelos como `text-embedding-3-small` (1536 dims, OpenAI) o `multilingual-e5-large` (1024 dims) dan muy buenos resultados.
¿Cómo sé si mi base de datos vectorial está funcionando bien?
Mide el recall de tu retrieval: del total de fragmentos que deberían aparecer para una consulta de prueba, ¿cuántos recuperas realmente? Si tienes un pipeline RAG completo, herramientas como RAGAS miden *context precision* (lo recuperado es relevante), *context recall* (recuperas todo lo necesario) y *faithfulness* (el LLM se ciñe a lo recuperado). Sin métricas, estás afinando a ojo.
¿Puedo usar una base de datos vectorial sin saber de machine learning?
Para usarla, sí. Las APIs de Pinecone, Qdrant o Chroma son razonablemente accesibles: insertas vectores, haces búsquedas. El modelo de embeddings también se puede usar como API (OpenAI, Cohere, Mistral) sin saber cómo funciona por dentro. Lo que sí necesitas entender son los parámetros de configuración del índice y las métricas de evaluación — de lo contrario, tomás decisiones a ciegas.
¿Cuánto cuesta operar una base de datos vectorial?
Depende mucho del volumen. Chroma en local es gratis. pgvector añade coste cero si ya tienes Postgres. Qdrant cloud tiene un tier gratuito generoso y luego escala por uso. Pinecone puede ser caro a escala — su modelo de pricing por "pods" o por usage conviene revisarlo antes de comprometerte. Milvus gestionado (Zilliz) es el más caro para grandes volúmenes pero también el más potente para esos casos.
¿La base de datos vectorial guarda el texto original o solo el vector?
Guarda ambas cosas: el vector y, opcionalmente, el payload (los metadatos + el texto original del chunk). Al recuperar un resultado, recibes el vector de vuelta (raramente lo necesitas) y el payload, que contiene el texto que pasarás al LLM como contexto. Qdrant lo llama "payload"; Weaviate lo llama "properties"; Pinecone lo llama "metadata". Mismo concepto, nombre diferente.
¿Qué tamaño de colección necesita una base de datos vectorial dedicada para tener sentido?
No hay un umbral exacto, pero como orientación: por debajo de 50.000-100.000 vectores, pgvector o incluso Faiss en memoria resuelven el problema sin añadir complejidad operacional. Por encima de 500.000 vectores con carga de consultas real, una base de datos vectorial dedicada empieza a aportar diferencias perceptibles en latencia y en capacidades de filtrado. Por encima de 5 millones de vectores, la diferencia es muy clara y la elección del índice (HNSW vs IVF y sus variantes) empieza a importar para el coste de infraestructura.
¿Cómo afecta la base de datos vectorial al coste de un sistema RAG?
El coste tiene tres componentes: el almacenamiento de los vectores (proporcional al número de documentos y a las dimensiones del embedding), la generación de embeddings (coste del modelo que convierte texto en vector — se paga una vez al indexar y de nuevo por cada consulta) y la infraestructura de la base de datos vectorial (managed como Pinecone cobra por uso; open source como Qdrant te cuesta el servidor). Para la mayoría de proyectos de empresa, el coste de la base de datos vectorial es pequeño comparado con el coste del LLM que genera las respuestas finales.
¿Funciona igual de bien en español que en inglés?
Depende casi enteramente del modelo de embeddings, no de la base de datos vectorial. La base de datos vectorial es agnóstica al idioma: solo almacena números. Lo que importa es que el modelo de embeddings haya sido entrenado con texto en español. Modelos multilinguales como `multilingual-e5-large`, `text-embedding-3-small` (OpenAI) o `jina-embeddings-v3` funcionan bien en español. Modelos entrenados solo en inglés producirán embeddings mediocres para consultas en español aunque la base de datos vectorial sea perfecta.
---
Si estás montando un agente que atiende a clientes sobre la base de conocimiento de tu empresa, la base de datos vectorial es la pieza que hace posible que ese agente encuentre la respuesta correcta en milisegundos entre miles de documentos. Lo que hay alrededor de esa búsqueda — el chunking, el modelo de embeddings, el reranking, la lógica del agente — es lo que construimos en GuruSup. Puedes ver cómo lo aplicamos en agentes de IA para empresas o profundizar en la arquitectura completa con nuestro software de base de conocimiento.